About Me
My name is Marc Brooker. I like to build things that work, and do cool stuff. I like building big things. I also dabble in machining, welding, cooking, and skiing.I am an engineer at Amazon Web Services (AWS) in Seattle, where I work on agentic AI, especially safety and policy for agentic AI. Before that, I worked on EC2, EBS, databases, serverless, and serverless databases.
All opinions are my own.
Links
My Publications and Videos@marcbrooker on Mastodon @MarcJBrooker on Twitter
Is this blog written by AI?
Good Performance for Bad Days
Two weeks ago, I flew to Toronto to give one of the keynotes at the International Conference on Performance Evaluation. It was fun. Smart people. Cool dark squirrels. Interesting conversations.
The core of what I tried to communicate is that, in my view, a lot of the performance evaluation community is overly focused on happy case performance (throughput, latency, scalability), and not focusing as much as we need to on performance under saturation and overload.

In fact, the opposite is potentially more interesting. For builders and operators of large systems, a lack of performance predictability under overload is a big driver of unavailability.

This is a common theme in postmortems and outage reports across the industry. Overload drives systems into regimes they aren’t used to handling, which leads to downtime. Sometimes, in the case of metastable failures, this leads to downtime that persists even after the overload has passed.
How did we get into this situation?
Not Measuring the Hard Stuff
At least one reason is immediately obvious if you pay attention to the performance evaluation in the majority of systems papers. Most of them show throughput, latency, or some other measure of goodness at a load far from the saturation point of the system.
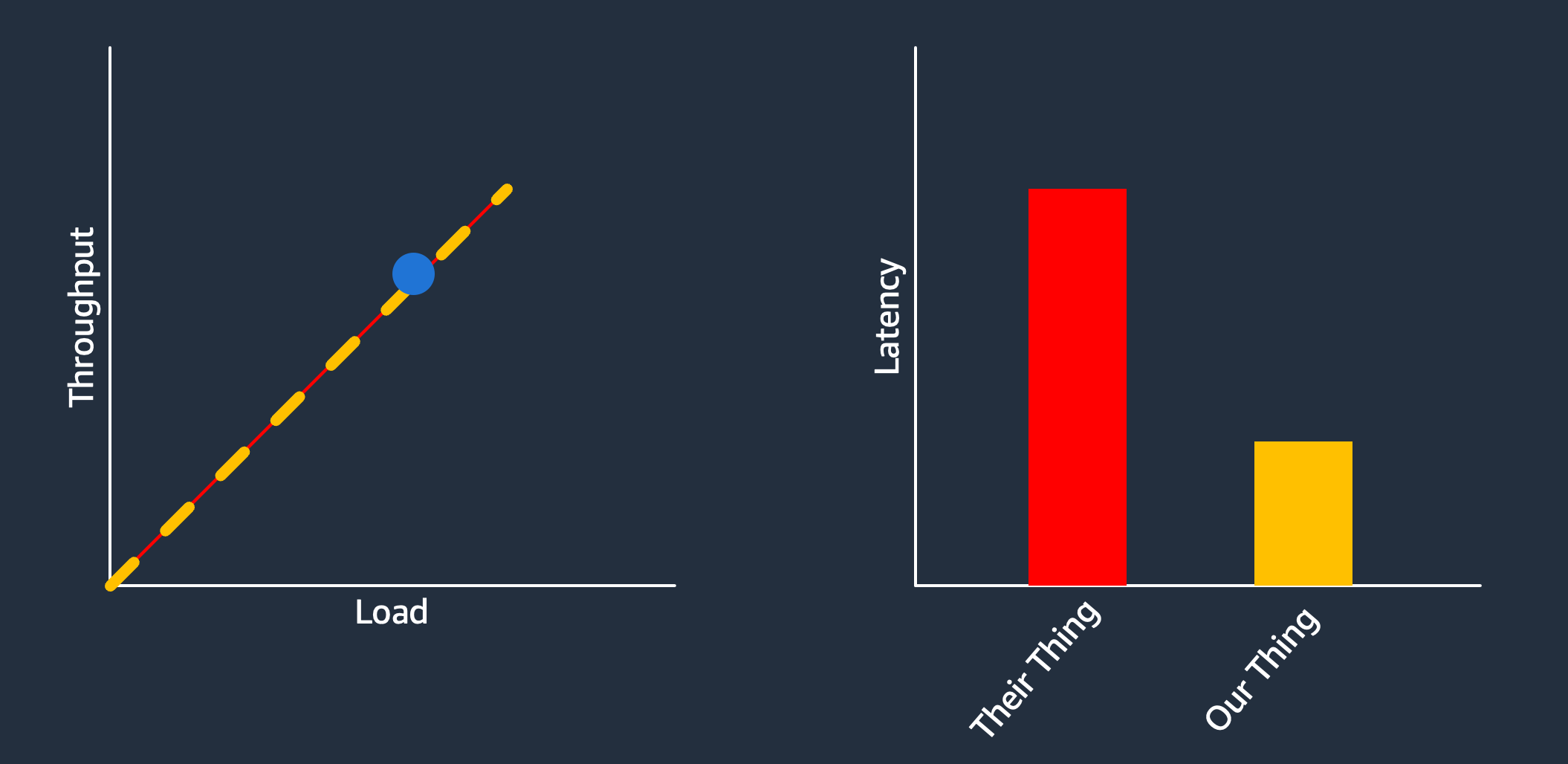
The first-order reason for this is unsurprising: folks want to show the system they built in a good light. But there are some second-order reasons too. One is that performance evaluation is easiest, and most repeatable, in this part of the performance curve, and it takes expertise that many don’t have to push beyond it.
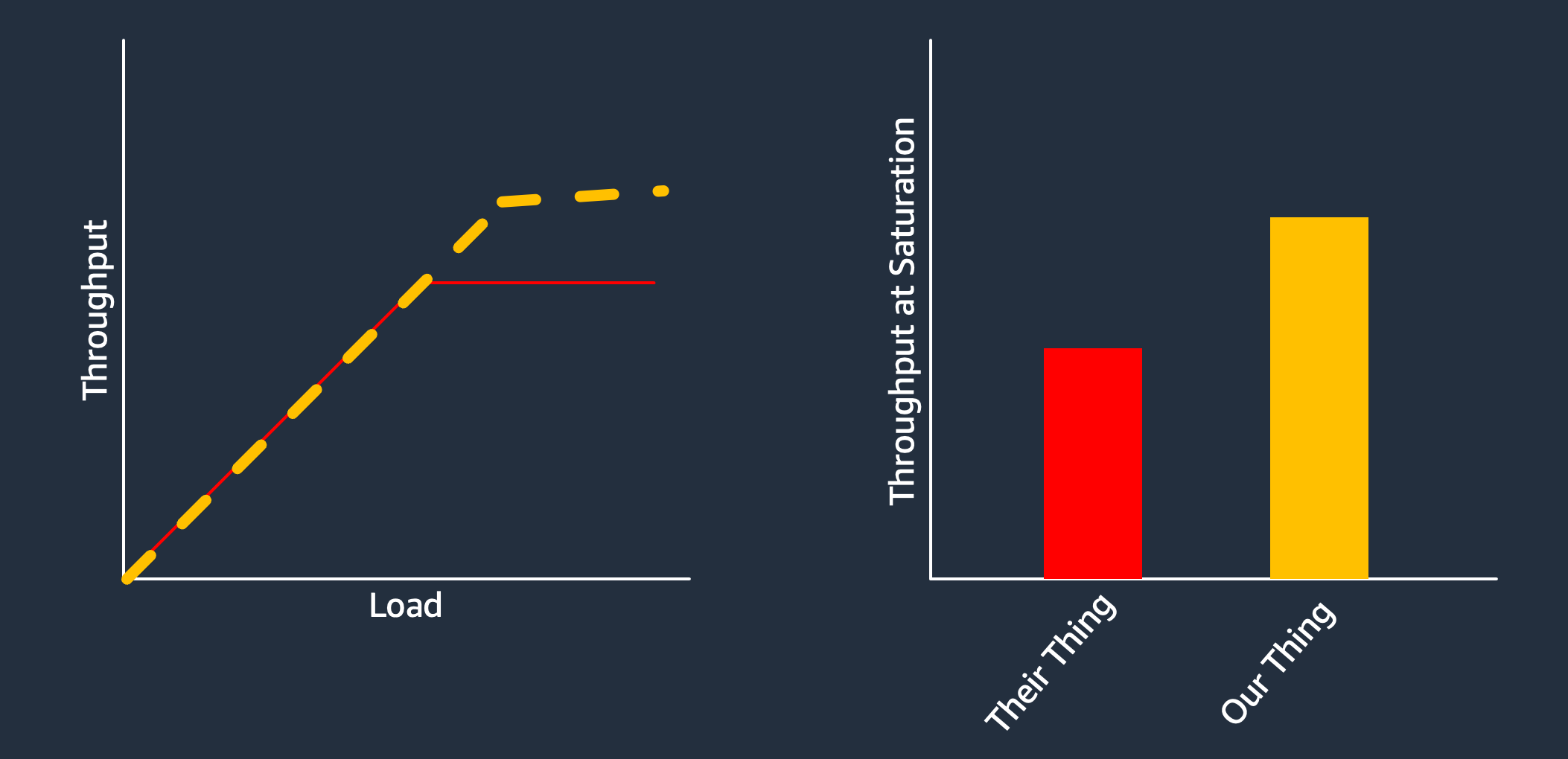
Some bolder authors will compare saturation points, showing that their systems are able to do more good stuff even when the load is excessive.
Only the boldest will go beyond this saturation point to show the performance of their system under truly excessive amounts of load, after the point where performance starts to drop.
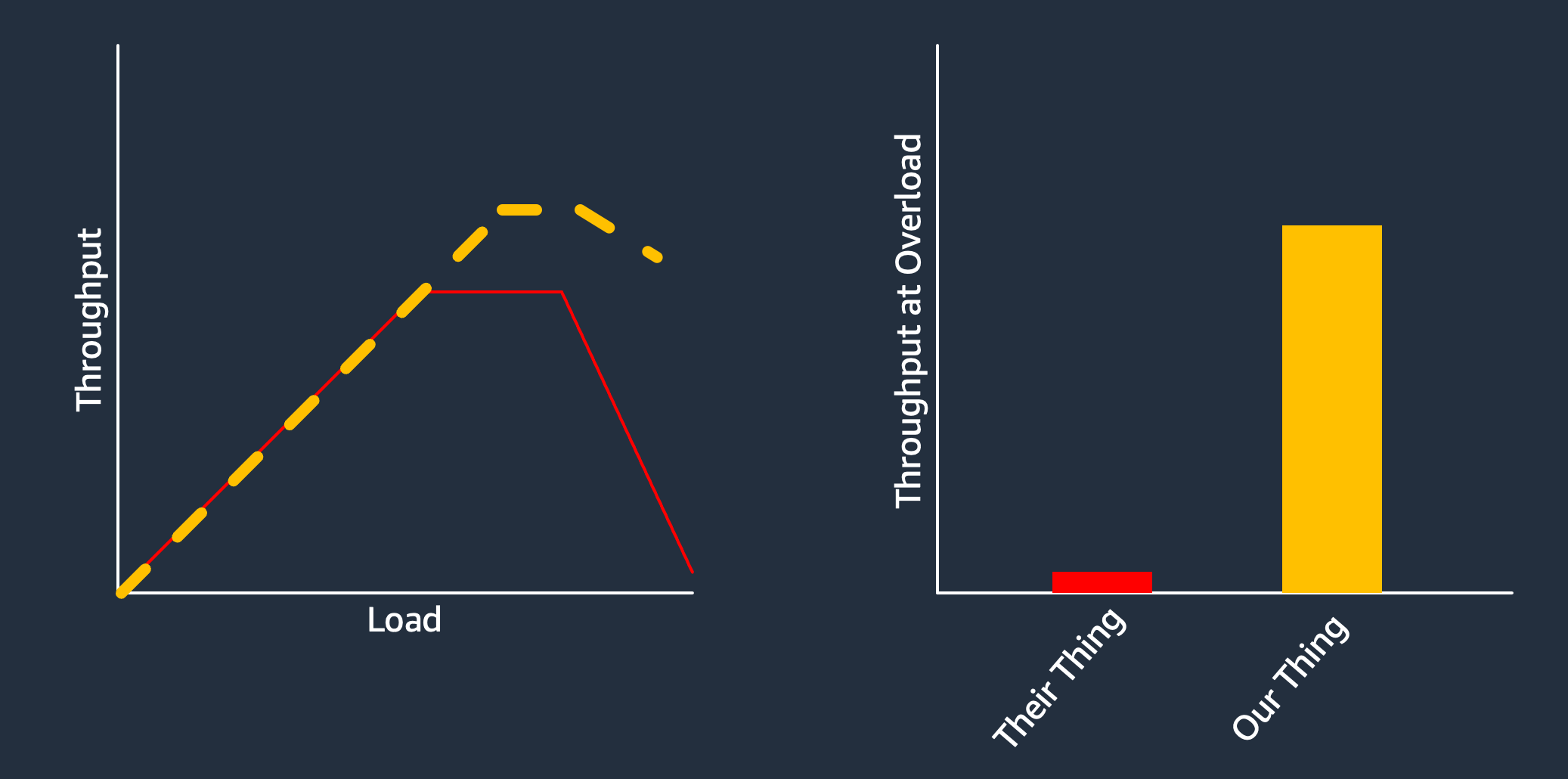
This regime is important, because it’s very hard to compose reliable end-to-end systems without knowing where the saturation points of components are, and how they perform beyond that point. Even if you try do things like rate limiting and throttling at the front door, which you should, you still need to know how much you can send, and what the backend looks like when it starts saturating.
As a concrete example, TCP uses latency and loss as a signal to slow down, and assumes that if everybody slows down congestion will go away. These nice, clean, properties don’t tend to be true of more complex systems.
Open and Closed
If you read only one performance-related systems paper in your life, make it Open Versus Closed: A Cautionary Tale. This paper provides a crucial mental model for thinking about the performance of systems. Here’s the key image from that paper:
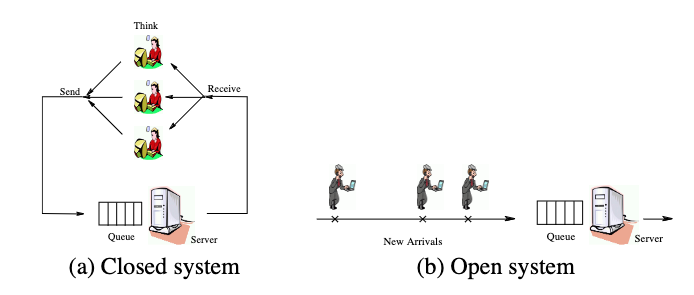
When we look at the performance space, we see two things:
- Most cloud systems are open (APIs, web sites, web services, MCP servers, whatever)
- Most benchmarks are closed (TPC-C, YCSB, etc)
That doesn’t make sense. The most famous downside of this disconnect is coordinated omission, where we massively underestimate the performance impact of tail latency. But that’s far from the whole picture. Closed benchmarks are too kind to realistically reflect how performance changes with load, for the simple reason that they slow their load down when latency goes up.
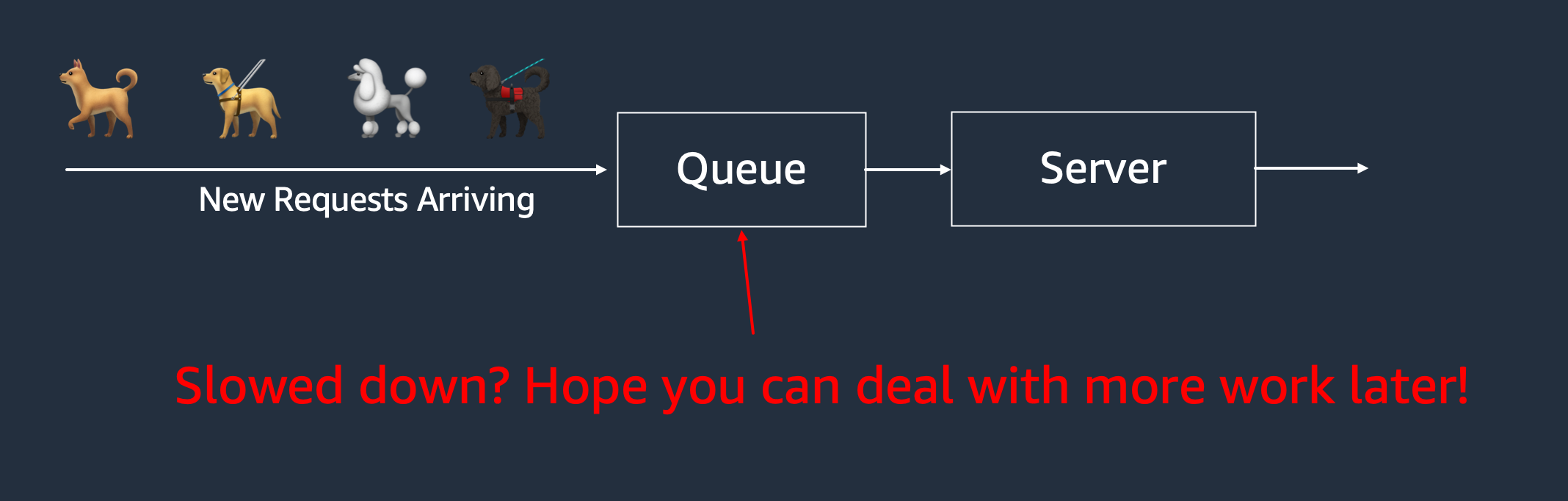
The real world isn’t that kind to systems. In most cases, if you slow down, you just have more work to be done later.
Metastability
As I’ve written about before (a few times, in different ways), metastability is a problem that distributed systems engineers need to pay more attention to. Not paying attention to performance under overload means not paying attention to metastability, where the majority of real-world triggers are overload-related.
Metastability isn’t some esoteric problem. It can be triggered by retries.
or by caches, as I’ve written about before.
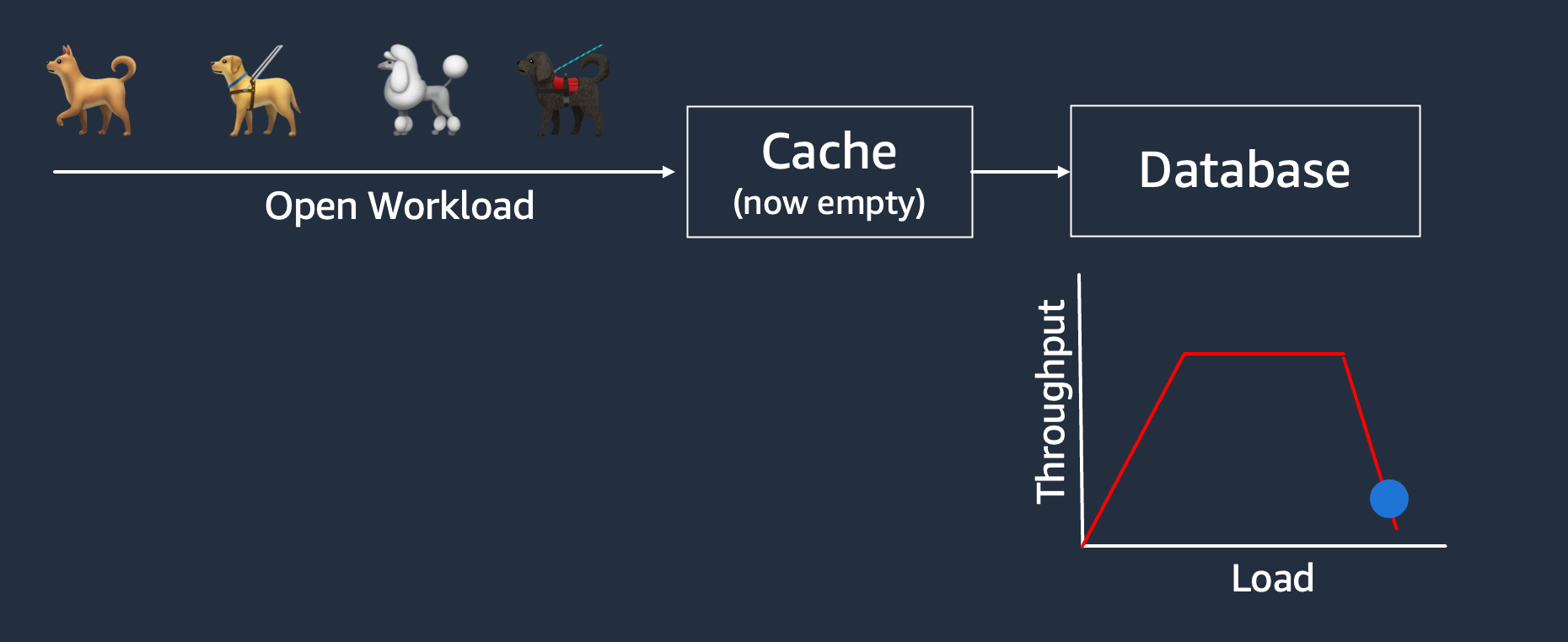
Disconnect between benchmark and real-world workloads
The other issue, as it always has been, is a disconnect between benchmark workloads and real-world workloads. This is true in that benchmarks don’t reflect the size and scale of work done by real-world systems.
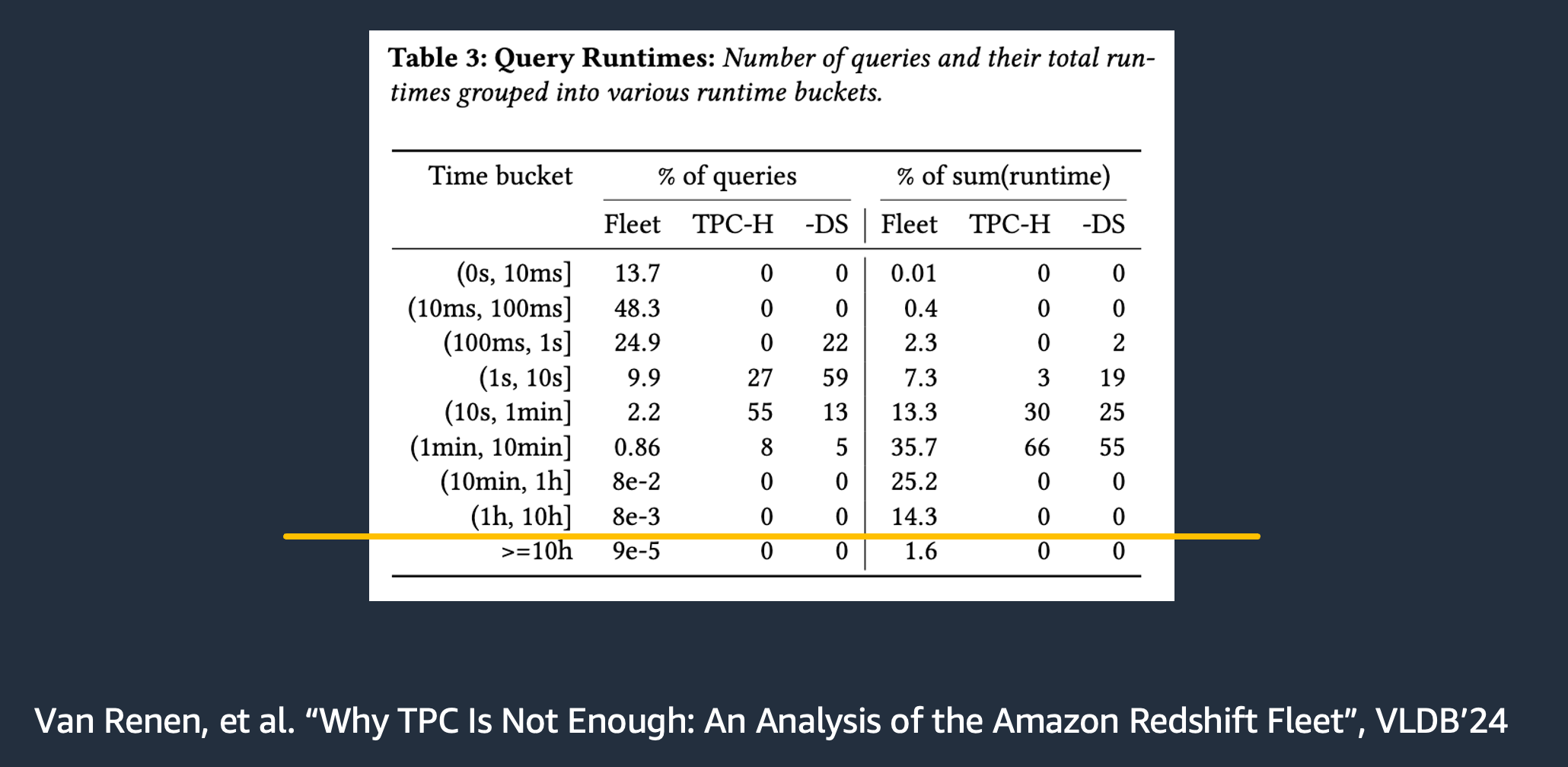
And in that they don’t reflect the coordination and contention patterns present in real-world workloads.

The example I used was TPC-C, which has coordination patterns that are much easier to scale than most real-world workloads. When visualized as a graph of rows that transact together, that becomes clear - you can basically partition on warehouse and avoid all cross-partition write-write conflicts.
Conclusion
Performance evaluation is super important to system designers and operators. This is a community I care about a lot. But I think there’s a growing disconnect between practice and theory in this space, which we need to close to keep the field relevant and alive.
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com