About Me
My name is Marc Brooker. I like to build things that work, and do cool stuff. I like building big things. I also dabble in machining, welding, cooking, and skiing.I am an engineer at Amazon Web Services (AWS) in Seattle, where I work on agentic AI, especially safety and policy for agentic AI. Before that, I worked on EC2, EBS, databases, serverless, and serverless databases.
All opinions are my own.
Links
My Publications and Videos@marcbrooker on Mastodon @MarcJBrooker on Twitter
Is this blog written by AI?
Garbage Collection and Metastability
I’ve written a lot about stability and metastability, but haven’t touched on one other common cause of metastability in large-scale systems: garbage collection.
GC is great. Garbage collected languages like Javascript, Java, Python, and Go power a big chunk of the internet’s infrastructure. Until Rust came along, choosing memory safety typically implied choosing garbage collection. For almost all applications, languages with garbage collection are a reasonable choice. The trade-offs between GC and not-GC have been well trodden, so I’m not going to spend time on any of them except one: metastability.
As we’ve discussed in prior posts, metastability comes about when systems have self-perpetuating cycles which permanently degrade goodput. Here’s what the cycle for GC might look like:
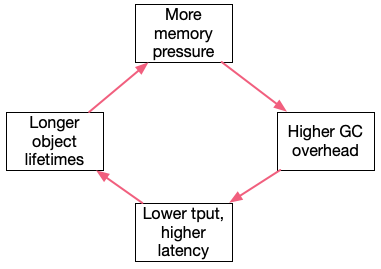
Increasing memory pressure increases the amount of time it takes for the GC to run, and increases the cost of handling any given request, this increases per-request latency and reduces throughput, this increases the number of requests in flight (and their associated per-request memory), which increases memory pressure. In a system that limits concurrency (whether a closed system or an open system with concurrency-limiting throttling) this isn’t likely to happen. In a system without limited concurrency (even if it does limit arrival rate), even a short-lived excursion can send the system into a mode where it spins around this loop until it collapses.
But do GCs behave that way?
The only controversial step in the loop is higher GC overhead, implying that increasing memory pressure increases per-request latency even in the presence of excess CPU (so it’s more than just the effect of memory management consuming more CPU, which would happen without GC). I’ve seen significant in-production evidence for that, and there seems to be some good evidence from the literature. For example, see Figure 2 from The DaCapo Benchmarks by Blackburn et al (from 2006):
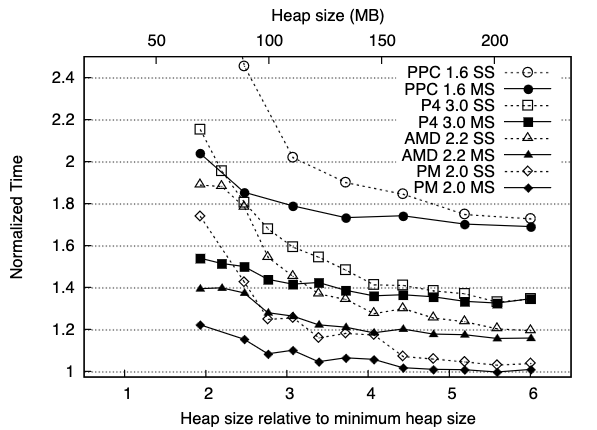
This effect seems to have become a little weaker with more modern GCs, but still very much exists. Here’s Table 6 from Distilling the Real Cost of Production Garbage Collectors by Cai et al from 2022:
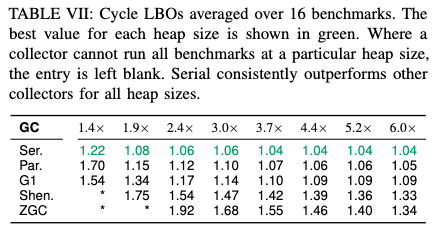
What we can see here is that, with some collectors, the cost of performing a unit of work can increase by up to 70% as memory pressure increases. Even up to nearly nearly 2x the minimum possible heap size, some collectors can’t make the work run at all.
Conclusion
It’s worth looking out for garbage collection as a potential cause of metastable behavior in open request-response systems. Both language-level GCs and similar systems (e.g. pool or arena allocators, uses of reference counting, etc) can display this behavior. Traditional memory management approaches (e.g. malloc and free) may display similar behavior, depending on how allocators are implemented (and, maybe, depending on how the underlying kernel is implemented).
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com