About Me
My name is Marc Brooker. I like to build things that work, and do cool stuff. I like building big things. I also dabble in machining, welding, cooking, and skiing.I am an engineer at Amazon Web Services (AWS) in Seattle, where I work on agentic AI, especially safety and policy for agentic AI. Before that, I worked on EC2, EBS, databases, serverless, and serverless databases.
All opinions are my own.
Links
My Publications and Videos@marcbrooker on Mastodon @MarcJBrooker on Twitter
Is this blog written by AI?
What’s Easy Now? What’s Hard Now?
This is the fourth in a series about how AI is changing software development, after It’s time to be right., What about juniors?, and My heuristics are wrong. What now?. It stands alone, but if you found this interesting you may also find those interesting.
I’ve been spending a lot of time thinking about the shape of the capabilities of coding agents. What they’re good at now, what they’re going to be good at. What they’re bad at now, how much of that is inherent and how much is transient. This is worth thinking about, because it’s the most important question shaping the future of software, and of software engineering. I don’t pretend to have an answer, but am coming to a conclusion that may be deeply counter-intuitive.
Coding agents are becoming very good indeed, and can build meaningful and correct software very quickly and at transformatively low cost. They have super-human abilities on some coding tasks. Of course, computer systems have had super human abilities for at least 85 years1. I think we’re going to find, as we have over those nine decades, that this new technology we’re building is vastly super-human in some areas2, and not nearly as capable as humans in others.
Which raises the important question of how, and why.
Feedback is powerful
Early on in my EE education, one of my professors drew a simple circuit on the board that’s been stuck in my mind ever since. It looked like this3:
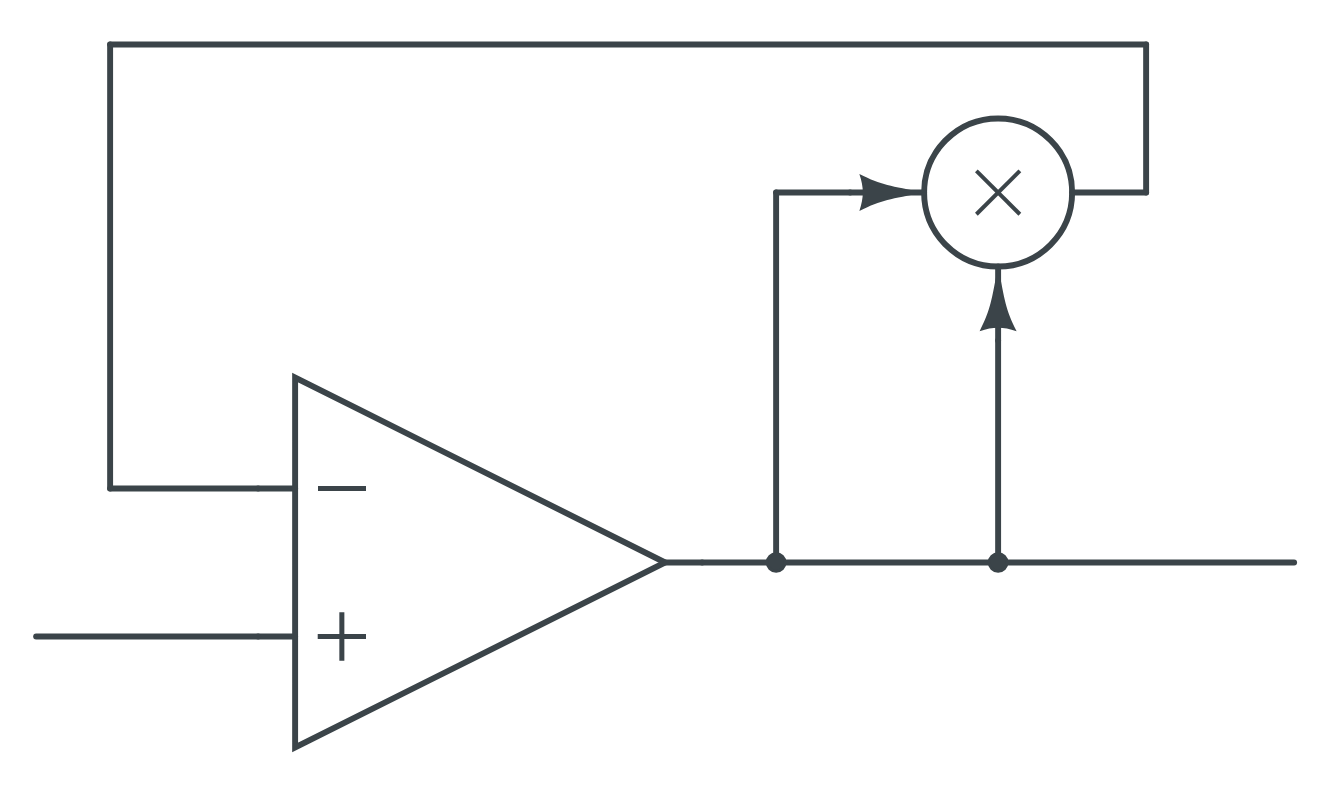
Apply a voltage on the left, and on the right you get the square root of that voltage4. The two components are an opamp and an analog multiplier IC (e.g. the deeply obsolete MC1495). This simple circuit encapsulates possibly the most important idea in electrical engineering: feedback is uniquely powerful. Maybe unreasonably powerful. It’s the idea that makes nearly every electronic device work, it keeps planes in the sky, and stops your oven from burning your dinner.
Components inside feedback loops can be made to behave significantly differently from their basic open loop behavior. Excellent outputs can be extracted from poor components. Multipliers can become square rooters. Feedback changes everything.
AI agents are just feedback loops. They’re built around a component with useful, but flawed, open loop behavior (an LLM), and use feedback to make that component able to do things that it’s not able to do without feedback. This is the basic idea behind the transformation that has happened in developer tooling in the last two years or so: a move from open loop AI (the smart autocomplete mode in IDEs) to agents. The moving of the feedback from the human developer (build, test, go back to IDE), into the agent itself (build, test, iterate).
Much of the conversation about long-term coding agent capabilities is about open loop model behavior. But that’s only half the picture. I may even stretch to saying it’s the less important half of the picture. Feedback is the thing that’s going to drive long-term capabilities.
The feedback loop hypothesis
In the long term, coding agents will find tasks with effective feedback ‘easy’, and tasks without effective feedback ‘hard’. The availability of accurate feedback will determine the limits on their capabilities.
On one hand, we should see this as uncontroversial. Anybody who has built code with agents knows that good error messages help keep agents unstuck. We’re seeing how tools like Rust guide agents towards writing correct code by providing explicit and immediate feedback about incorrectness of some kinds. We’re seeing agents be great at performance work, where good benchmarks exist. We’re seeing tools like property-based testing be uniquely valuable. We’re also seeing that agents aren’t great at architecture (where feedback tends to be of the ‘I know it when I see it’ kind), or writing concurrent programs (where feedback tends to be of the ‘it silently corrupted data at runtime’ kind).
But let’s look forward a little bit, and compare two problems:
- Building a delightful ergonomic photo editing website.
- Building a correct high-performance database storage engine5.
For open-loop models, the former is easier than the latter. At least in that you’ll get closer to real success with a pure vibe coding workflow, and much closer to success on the former after a single shot. The feedback loop hypothesis, however, makes me think that the latter is actually the easier long-term problem.
To understand why, consider their feedback loops. The website’s feedback loop, beyond maybe some automation that tests if the buttons do what they should, requires a human in the loop. It needs to be easy to use for humans, and humans are notoriously slow, squishy, and inconsistent feedback providers. The latter, however, has a rather simple specification, including the API, safety properties, and liveness properties. With the right tools in the feedback loop, iteration towards success requires no humans.
What does it mean?
I think this is different from the intuition many people have about coding agents. They see websites and UIs as ‘easy’ (see the SaaSpocalypse), and system software as ‘hard’. The feedback loop hypothesis says that this is backwards. That, in fact, we’re going to find that SaaS is ‘hard’ and system software is ‘easy’.
This is going to raise the importance of specification (the writing down of what good looks like to drive the feedback loop), and of tools that apply that specification to code. Compile-time tools like Rust, Hydro, and Verus. Modelling-time tools like TLA+ and P. Specification tools like Kiro’s spec analyzer. Testing tools, simulators, mocks, etc.
The future of software development is building these feedback loops. Many hard problems remain.
Footnotes
- Dating back to the work of folks like Marian Rejewski in the 1930s.
- The MacBook on my desk can add 64 bit numbers about something like 100,000,000,000 times faster than I can.
- Drawn with CircuitLab, and adapted from this Electronics StackExchange Answer. In reality, a few more passive components are needed.
- If you’re not familiar with this stuff, here’s an intuition for how this works. The opamp (the triangle) tries to adjust its output (on the right) so the two inputs are the same. So if you take the output, and multiply it by itself, then feed it into one of the inputs, it’ll set the output to the square root of the input. If you are familiar with this stuff, I apologize deeply for that explanation.
- I mean something on the scale of, say, RocksDB or InnoDB, not something on the scale of Aurora DSQL or even PostgreSQL. I think these large-scale distributed systems are going to be harder to hill climb to, at least for the future I can see.
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com