About Me
My name is Marc Brooker. I've been writing code, reading code, and living vicariously through computers for as long as I can remember. I like to build things that work. I also dabble in machining, welding, cooking and skiing.I'm currently an engineer at Amazon Web Services (AWS) in Seattle, where I work on databases, serverless, and serverless databases. Before that, I worked on EC2 and EBS.
All opinions are my own.
Links
My Publications and Videos@marcbrooker on Mastodon @MarcJBrooker on Twitter
It’s time to be right.
Earlier this week, I spoke at AI Dev 26. This is what I spoke about there.
I’ve been making money, in some form, building software for nearly 30 years. The last five months have been the most exciting of that entire time. I’m extremely optimistic about the future of software, and the future of software engineering as a field.
But I have a hypothesis about agentic AI for development, and for knowledge work broadly: in future, the size of the opportunity for agentic AI will be more limited by defect rate than capabilities.

Let’s break that down a little bit, by thinking about defects along two axes: how serious the defects are, and how frequent they are. These axes intentionally conflate two inputs—how hard the problems are and how capable agents are at solving them—and focus only on the output that matters most: user-experienced defects. We’re also focusing on outputs from an AI agent here. Agents are feedback loops. Feedback loops, just like in electronics and control theory, can have significantly different capabilities from their underlying components. In simpler terms, agents can work around model gaps very effectively1.
![]()
Simplifying further, we’ll arrange these axes into a kind of four-blocker, and think about the kinds of people that would use an agent in each block.
- High defect frequency, high defect seriousness. Basically nobody. Except maybe a small set of true believers and early adopters. If an agent is making highly consequential mistakes often, it’s simply not going to be useful to a lot of folks.
- High defect frequency, low defect seriousness. People working on problems where slop is OK. This is a larger opportunity, because slop is OK fairly frequently. If I’m using an agent for low consequence stuff, like summarizing an email about this fall’s soccer league, it’s likely to do a better job than I’d do by skimming. And, as much as it tends to hurt our sense of professional pride, there’s also a huge opportunity for software slop in one-off scripts, little experiments and tools, basic UIs, and so on. Even stability-sim.systems is, in some sense, slop.
- Low defect frequency, high defect seriousness. This is an odd corner, where the opportunity is mostly constrained to a set of experts. Software built here is going to need to be reviewed, debugged and operated by people who deeply understand how it works. Often, that debugging is going to require significantly more understanding than it took to build the software in the first place. That doesn’t make agentic AI useless, but does severely limit the set of people who can get value out of it.
- Low defect frequency, low defect seriousness. This is where we want to be, because it means that everybody can play. The defect rate is low enough that it’s not annoying or time wasting, and the defects are low-consequence enough that those which remain don’t matter.

Again, I’m conflating the difficulty of the problem with the capabilities of the agents here. Easier problems move towards the top left more quickly. The point, though, is that defect rate is going to be one of the main inputs into how many people can use an agent, irrespective of how well it does on its best days.
We can also frame the problem as a distribution of outcomes. The right tail is the positive capabilities that agents have, and is the part of the distribution that gets the most attention and effort. The left tail is the defects, the bad outcomes, which doesn’t get nearly as much attention but is probably more important as an area to invest in if you care about serving real customers and growing a real business on AI agents.
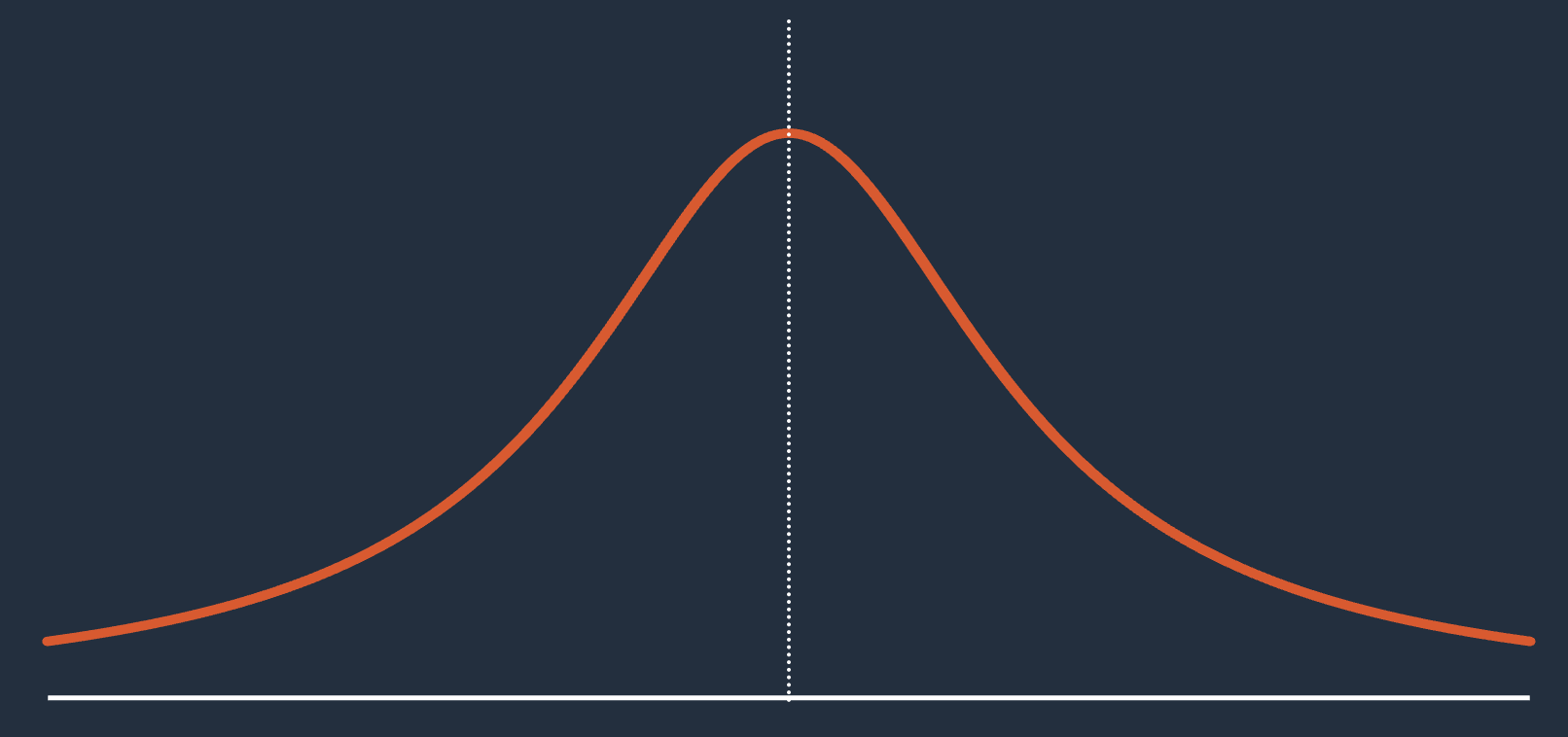
Somewhat amusingly, my favorite knowledge work agent took five tries to draw this Cauchy distribution SVG. The first version was a normal distribution, and the next three were weirdly spiky or discontinuous. At each step it insisted it was me that was wrong about what a Cauchy distribution looks like. Solidly in the bottom left corner here2.
I want to highlight some of the work we’re doing at AWS on agent correctness. This is just a sample of a large body of work, but shows the direction we’re heading it.
- Correct-by-construction coding tools and languages, like Hydro for distributed systems, and Cedar for auth. These are tools that agents can use to avoid entire classes of high-consequence defects3.
- Spec-driven development in agents like Kiro, which gives the coding agent additional big picture context that helps it evolve systems over time without regressing on key properties. Property-based testing is another example of the same pattern at a different scale.
- Code reasoning tools like Strata, powered by Lean, that allow agents to reason formally about properties of code.
- Autoformalization, turning natural language into precise formal implementations, in Bedrock AR Checks and AgentCore Policy, which remove whole classes of runtime defects (especially in critical places like tool call safety).
- Deterministic and precise policy for tools, in Trusted Remote Execution and AgentCore Policy, which precisely constrain agents tool call behavior.
- Principled approaches to deterministic agent steering, like Strands Steering, which can keep agents on the right path while still taking advantage of their power and flexibility.
This is also something that needs an industry-wide focus and attention, and not something we can do just by building tools. Some changes I’d like to see are:
- Benchmarks which capture failure severity, not just pass/fail. Pass@10 isn’t super meaningful if the other 9 swings were subtly and non-obviously wrong in consequential ways.
- An end to end view of dev agent success, not just code patching. Operations, cost, availability, durability, availability, security, performance, stability, etc. These are things that customers of software care about deeply, and aren’t captured well in existing benchmarks.
- A research program to develop a deep understanding of agentic AI failure modes, and a taxonomy of failures.
- A culture where we take our worst days as seriously as our best ones. In my recent conversation with Ryan Peterman I spoke a lot about AWS’s culture around learning from failures, and I think that’s a pattern we need industry-wide focus on in agentic AI.
As I said up front, I’m super optimistic about the future of this field. But I think that a lot of the conversation about risks is either silly sci-fi stuff, or straight-up denialism aimed at the right hand side of the distribution. There’s a really smart and important conversation to be had about the left hand side, but too few people having it today.
Footnotes
- But also hide model capabilities. Bad agentic harnesses and the wrong feedback can make a great model bad, and great feedback can make a bad model much better.
- I knew people would accuse me of being insufficiently bitter lesson pilled after this talk. The choice of the Cauchy distribution is a little easter egg for those people.
- Memory-safe languages like Rust are also in this category.
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com