About Me
My name is Marc Brooker. I like to build things that work, and do cool stuff. I like building big things. I also dabble in machining, welding, cooking, and skiing.I am an engineer at Amazon Web Services (AWS) in Seattle, where I work on agentic AI, especially safety and policy for agentic AI. Before that, I worked on EC2, EBS, databases, serverless, and serverless databases.
All opinions are my own.
Links
My Publications and Videos@marcbrooker on Mastodon @MarcJBrooker on Twitter
Is this blog written by AI?
NoSQL: The Baby and the Bathwater
This is a bit of an introduction to a long series of posts I’ve been writing about what, fundamentally, it is that makes databases scale. The whole series is going to take me a long time, but hopefully there’s something here folks will enjoy.
On March 12 2006, Australia set South Africa the massive target of 434 runs to chase in a one-day international at the Wanderers in Johannesburg. South Africa, in reply, set a record that stands to this day: 438 runs in a successful chase. It’s hard to overstate what an outlier this was. The previous record for a successful run chase was only 332. Despite nearly two decades of bigger is better scores in cricket, nothing has come close.
It wasn’t just cricket scores that were getting bigger in the mid 2000s. Databases were too. The growth of the web, especially search and online shopping, were driving systems to higher scales than they had ever seen before. With this trend towards size came a repudiation of the things that had come before. No longer did we want SQL. No, now we wanted NoSQL.
There are various historical lenses we can apply to the NoSQL movement, from branding (No SQL or Not Only SQL), to goals (scalability vs write availability2 vs open source), to operations (should developers or DBAs own the schema? Should DBAs still exist?), but there was clearly a movement1 with at least some set of common goals. In this blog post I’m going to single-mindedly focus on one aspect of NoSQL: scalability. We’ll look at some of the things the NoSQL movement threw out, and ask ourselves whether those things actually helped achieve better scalability. On the way, we’ll start exploring the laws of scalability physics, and what really matters.
So what did NoSQL throw out? Again, that varies from database to database, but it was approximately these things:
- Explicit schema
- Transactions
- Strong consistency
- Joins, secondary indexes, unique keys, etc.
- The SQL language itself
Looking through the lens of scalability, let’s consider the effect of these. Which were the dirty bathwater, and which the baby?
What is Scalability? At the risk of over-simplifying a little bit, scalability has basically two goals:
- Increase the throughput of the database across the entire key-space beyond what a single machine can achieve. This is typically done with some variant of sharding4.
- Increase the throughput per key beyond what a single machine can achieve. This is typically done with some variant of replication5.
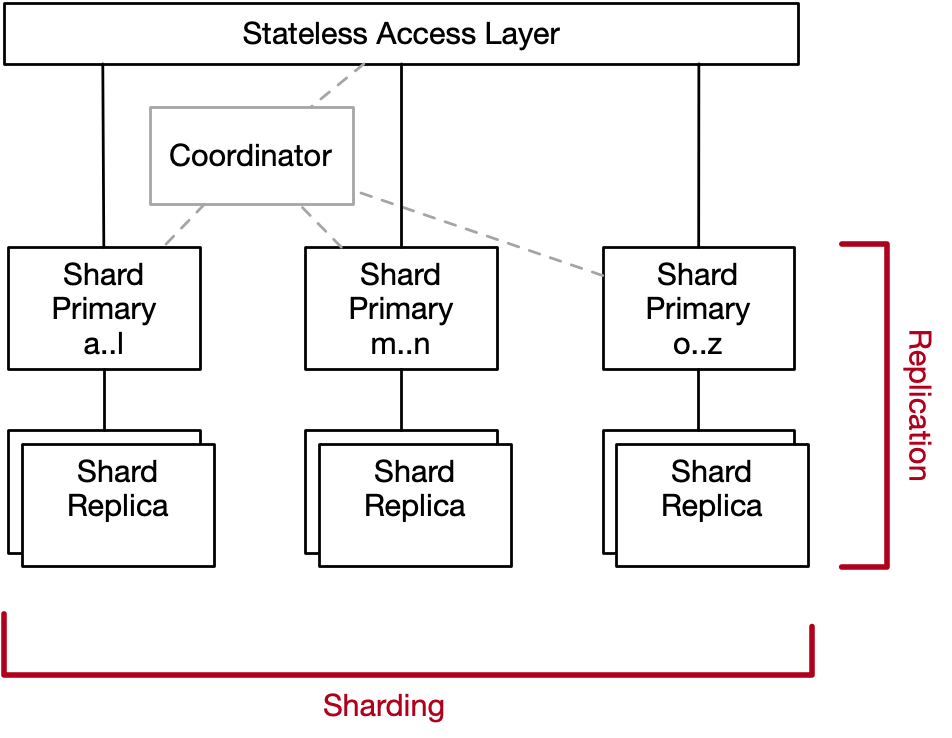
Replication simply means that we keep multiple copies of each data item, and do some work at write time to keep those copies up-to-date. In exchange for that work, we get to read from the additional copies, which means we get to trade write-time work and read-time scalability in a useful way.
Sharding simply means that we break the data set up into multiple pieces along some dimension. Unlike with replication, there isn’t a work tradeoff here: for reads and writes that touch just one item, nothing limits the scalability of the database (in theory) until we have as many shards as items.
Things that limit scalability are things that restrict our ability to apply these two tools. For example:
- Things that require shards to work together (coordination) limit the effectiveness of sharding,
- Things that require readers to coordinate with writers limit the effectiveness of replication,
- Things that send a lot more work to some shards than others (skew) limit the effectiveness of sharding.
On the other hand, things that are merely expensive to do (like compression, encryption, schema enforcement, or query parsing) may be very interesting for performance, but not particularly interesting for scalability. In short, it is coordination that limits scalability. We can use this lens to revisit each of NoSQL’s simplifications.
Explicit Schema Schema, itself, is mostly a local (item-by-item or row-by-row) concern, and therefore discarding it doesn’t do much for scalability. On the other hand, schema brings with it easy access to a set of features (auto-increment, unique keys, etc), and a set of design patterns (normalization and its horsemen), that are extremely relevant to scalability. We’ll get to those when we talk about database features in a little bit. The other common point about schema is an operational scale one: changing schema in the database can be slow and risky, both because of the operation itself3, and because of the complexity of applications that depend on that schema. NoSQL’s movement to application-defined schema was a reaction to this operational reality, largely based on the idea that moving schema into the application would simplify these things. Reports of the success of this approach are mixed.
Transactions Transactions clearly require coordination. You’re asking the database to do this thing and that thing at the same time. Atomic commitment, needed for the A and I in ACID, is particularly difficult to scale. While there are approaches to reducing the amount of coordination needed6, dispensing with it entirely is clearly a significant scalability win.
But, of course, it’s not that simple. The cost of transactions depends on the isolation level. For example, serializability requires readers to coordinate with writers10 on each key, while snapshot isolation only requires writers to coordinate with writers. Lower levels require even less coordination. Second, whether coordination limits scalability in practice depends a lot on the access patterns. If Alice and Bob are working together, and Barney and Fred are working together, then we may be OK. If sometimes Alice works with Bob, and sometimes with Fred, and Barney works with everybody some of the time, then coordination may be much more expensive.
As we go through the series we’ll look at this in detail, but for now, it’s true that transactions play a big role in scalability. But the relationship between transactions and scalability is complicated, and its not clear that you get a lot of scalability just from throwing out transactions9. Throwing out all transactionality in the name of scalability seems unnecessary.
Strong Consistency Like transactions, the scalability of strong consistency is a deep topic that will get its own post in this series. Clearly, relaxing consistency makes some things significantly easier. For example, many systems (like DynamoDB), implement read scale-out fairly simply by allowing readers to read from replicas, without ensuring those replicas are up-to-date. This is clearly a nice simplification, but its not clear that it is strictly required to achieve the same level of scalability7.
Strong consistency may be something NoSQL didn’t need to throw out.
Joins, Secondary Indexes, Unique Keys, etc This category is a bit of a grab bag, and there seem to be at least three different categories here:
- Joins and friends, which introduce read skew, and therefore make it more difficult to scale out the read path of the database through sharding. Read skew is related to the laws of physics in an interesting way, because it doesn’t matter much in isolation, but matters a great deal in the presence of writes. Read skew aside, its not clear joins affect scalability much at all.
- Secondary indexes and friends, which introduce potential write skew (driven by index cardinality). Unlike read skew, write skew is a problem in itself, because we can’t throw replication at it in the same way.
- Unique keys and friends (including sequences, auto-increment, etc) which are inherently scalability killers, because they require coordination and create write skew. Auto-increment and friends is potentially the worst case here, because it may force the database to serialize all writes through a single sequencer8. Relaxing semantics may help, but that’s always true.
The SQL Language Itself This is the controversial one. There are two ways to look at this. One is that the language has no influence at all on scalability, because it’s just a way of expressing some work for the database to do. The other is that SQL’s semantics (such as ACID) and features (such as secondary indexes) mean that the scalable subset of SQL is small and hard to find, and so throwing out SQL is a win in itself.
This is an interesting argument. SQL is more than a language, but a set of semantics and features and expectations and historical behaviors, all rolled into a ball. If you throw out SQL, then you can throw out all of those things, and package scalable semantics and features together in a new API. This baby has been in the bath a very long time, and it’s no longer clear where one ends and the other begins.
The other argument to be made here is that SQL, as this declarative high-level language, makes it very easy for a programmer to ask the database to do expensive things (like coordination) in a way that may not be obvious. Lower-level APIs (like, as I’ve argued before, DynamoDB’s) make it much easier for the programmer to reason about what they are asking the database to do, and therefore reason about scalability and predictability. Alternatively, lower-level APIs force programmers to understand things about the system that may be hard to hide. To avoid falling into the classic are abstractions good? question, I’ll simply point out that this is a key issue that I expect we’ll be grappling with forever.
But mostly, SQL is a distraction. It’s the least important thing about NoSQL.
Conclusion NoSQL, as fuzzy as it is, is a perfect example of the pendulum of technical trends. Even if we look at it just through the very limited lens of scalability, its clear that the movement identified some very real issues, and then overreacted to them. At least some of this overreaction was for good reasons: the best of both approaches are complex and difficult to build, and so overreacting helped create a lot of systems that could solve real issues without solving those hard problems. That’s a good thing. On the other hand, at least some of it was because of a misunderstanding of what drives scalability. Its hard, without being in people’s heads, to know which is which, but we can know better now.
Footnotes
-
In this post, I separate the NoSQL movement for transactional applications from the movement away from (only) SQL for analytics applications, perhaps most famously MapReduce and friends. My focus here is on transactional applications (OLTP), while being clear that there isn’t a bright line between these things.
-
Write availability is a key concern in Werner Vogels 2009 article Eventually Consistent, which is a great summary of the state of the argument there. Availability is extremely important, but I’m not focusing there because I think it’s a topic that’s been very well covered already.
-
Who among us haven’t enjoyed sweaty minutes or hours waiting for that ALTER TABLE to complete, while praying it doesn’t break replication?
-
Of course, for both replication and sharding there are a million different ways to (ahem) feed a cat. I’m not getting into those here, because I don’t think they matter a lot to the underlying dynamics. If you’re interested in the variants, check out Ziegler et al Is Scalable OLTP in the Cloud a Solved Problem?, or the Calvin paper, or the Tapir paper, or the Dynamo paper, or the DynamoDB paper, or the Spanner paper, etc. etc.
-
Replication is also important for durability, availability, and other important things.
-
For example, see Bailis et al’s work on Highly Available Transactions, Wu et al’s work on Anna, and Calvin and the extended deterministic database universe, for different looks at the nature of the coordination needed for transactions.
-
It is strictly required in the asynchronous model, but we don’t live in the asynchronous model.
-
Coordinate ALL THE THINGS! That’s a current reference the kids will get, right?
-
I like how Doug Terry makes this point in Transactions and Scalability in Cloud Databases—Can’t We Have Both?
-
Specifically for read-write transactions, that is. Read-only readers can be serializable with no coordination with writers or other readers, provided a reasonable set of assumptions and constraints.
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com