About Me
My name is Marc Brooker. I've been writing code, reading code, and living vicariously through computers for as long as I can remember. I like to build things that work. I also dabble in machining, welding, cooking and skiing.I'm currently an engineer at Amazon Web Services (AWS) in Seattle, where I work on databases, serverless, and serverless databases. Before that, I worked on EC2 and EBS.
All opinions are my own.
Links
My Publications and Videos@marcbrooker on Mastodon @MarcJBrooker on Twitter
DSQL Vignette: Wait! Isn’t That Impossible?
In today’s post, I’m going to look at how Aurora DSQL is designed for availability, and how we work within the constraints of the laws of physics. If you’d like to learn more about the product first, check out the official documentation, which is always a great place to go for the latest information on Aurora DSQL, and how to fit it into your architecture.
In yesterday’s post, I mentioned that Aurora DSQL is designed to remain available, durable, and strongly consistent even in the face of infrastructure failures and network partitions. In this post, we’re going to dive a little deeper into DSQL’s architecture, focussing on multi-region active-active. Aurora DSQL is designed both for single-region applications (looking for a fast, serverless, scalable, relational database), and multi-region active-active applications (looking for all those things, plus multi-region, synchronous replication, and the ability to support active-active applications).
Aurora DSQL’s Multi-Region Architecture
Let’s start by dipping into Aurora DSQL’s multi-region architecture. We’ll focus on multi-region clusters here, because they highlight the trade-offs best, but the same rules apply to single region clusters if we substitute AZ for region. In a multi-region DSQL cluster1 each of two regions runs a nearly complete copy of the cluster’s infrastructure: a full copy of storage, enough Query Processors (QPs) to handle the load, and so on. The exception is the adjudicator: the leader adjudicator for each shard exists in only one region at a time. We’ll come back to that, because it’s a key part of the story.
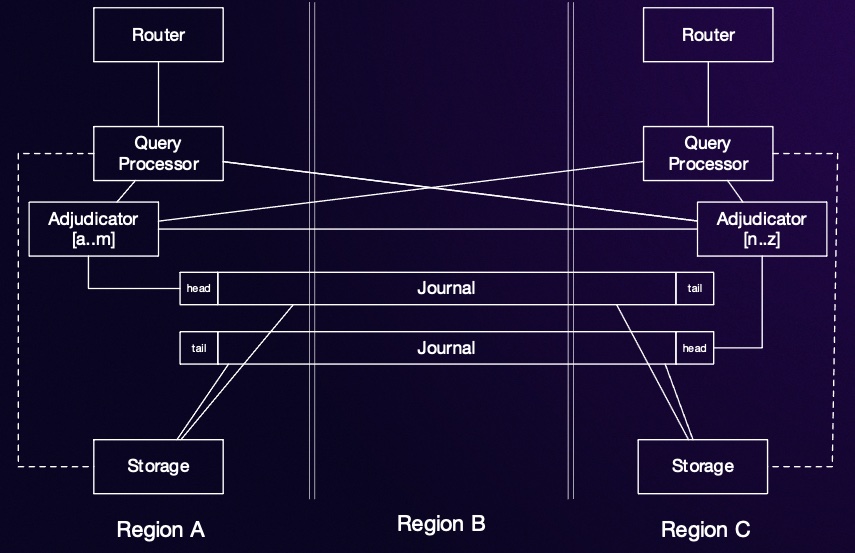
What benefits does this architecture offer?
- Symmetric latency for active-active multi-region architectures. The read, write, and commit latency you’ll see will be very similar from both regions (this is unlike databases that do write forwarding, or have a primary region, where there’ll be one “fast” region and one or more “slow” regions).
- Strongly consistent reads in both regions, at in-region latency, even for reads in read-write transactions (and remember that those
UPDATEs and even someINSERTs are read-modify-writes, so this matter even if you aren’t doing anySELECTs). - Strong isolation for transactions in both regions.
- Cross-region durability for committed transactions: the Journal ensures data is persisted in multiple regions when transactions commit.
You’ll notice there are three regions here: two regions with DSQL endpoints and full copies of the data, and one witness region with only a copy of the Journal. That’s going to become important as we turn to discussing failures.
What happens during a partition?
Next, we’ll turn our attention to what happens during the time when one of the three regions is disconnected and not available. In the case it’s the witness region that’s disconnected, nothing customer-observable happens (except a small increase in COMMIT latency for some configurations3). However, if one of the two full regions because uncontactable, then DSQL makes an important decision.
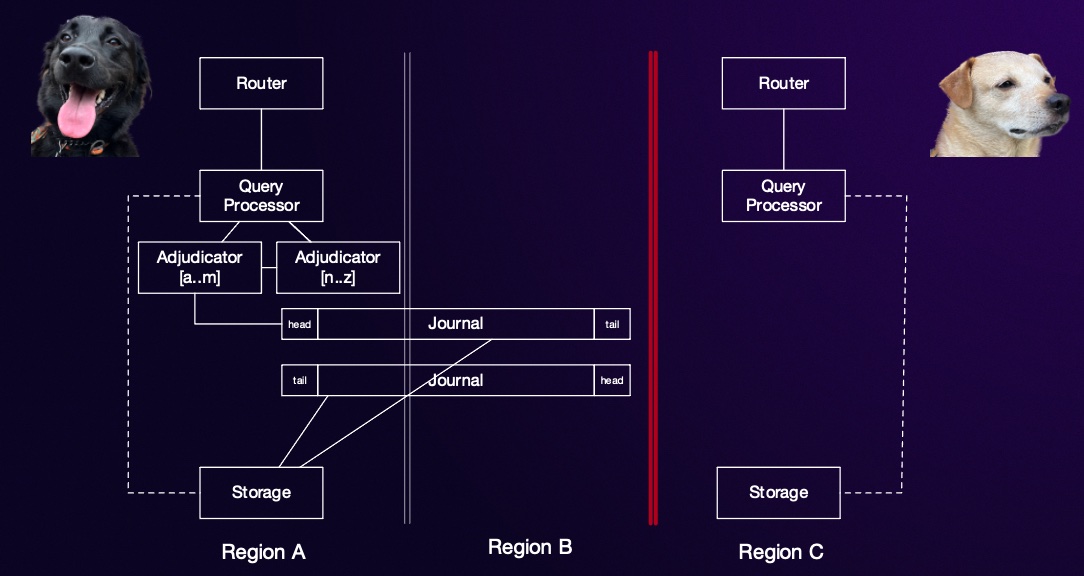
When one of the two full regions becomes unavailable (partitioned off if you like the CAP terminology), the DSQL endpoint in that region becomes unavailable for both reads and writes. The endpoint in the other region (the one on the majority side) remains available, and continues to offer strong consistency, isolation, and multi-region durability. Applications can send their customers to the healthy region, and end customers can observe no unavailability.
Some statements of the CAP theorem make it sound like this is an impossible option, but that’s not true: there’s no theoretical or practical constraint on continuing to provide availability and strong consistency on the majority side of a network partition, as long as we don’t accept writes on the smaller side. I wrote a blog post about this a couple months back: Lets Consign CAP to the Cabinet of Curiosities.
Going back to the diagram, you’ll notice that one thing did need to move: the adjudicators that were in the disconnected region. Moving the adjudicator leader to the majority partition allows that partition to start making adjudication decisions. In the Aurora DSQL design, the adjudicator contains no durable or persistent state, so this move requires only recreating its small amount of transient state on the majority side. This side knows all committed transactions, and so knows everything it need to know to recreate the adjudicator state. Storage was already fully replicated, and so there was no need to move it.
This is another benefit of the choice of OCC. In a pessimistic locking design, if lock state is lost there’s no choice but to abort all ongoing transactions. In our OCC-based design, the adjudicators state doesn’t depend on ongoing transactions at all, and can be reconstructed only from the set of committed transactions. The adjudicators don’t even know about the running transactions, and will never come to learn about read-only transactions at all.
Taking advantage of these properties
We’ve covered what happens inside DSQL’s architecture. Next, let’s consider what that means for patterns of building multi-region applications on DSQL. First, I think that active-active architectures are the best choice for many multi-region application architectures. This simply means that both sides are actively taking customer traffic at all times (except during failures, when you move everybody over to one side). I think this for a few reasons:
- Having both sides taking traffic helps you know that both sides are actually working, correctly provisioned, and able to take traffic. This avoids surprises2.
- You can take advantage of DSQL’s fast local writes and reads, and equal-from-all-endpoints
COMMITperformance, to offer lower latency to customers by pointing them at the application close to where they are (Route53 can be a great way to do this). - It keeps caches full and JITs warm inside your application, avoiding latency spikes when traffic needs to be rerouted.
Here’s what that looks like:
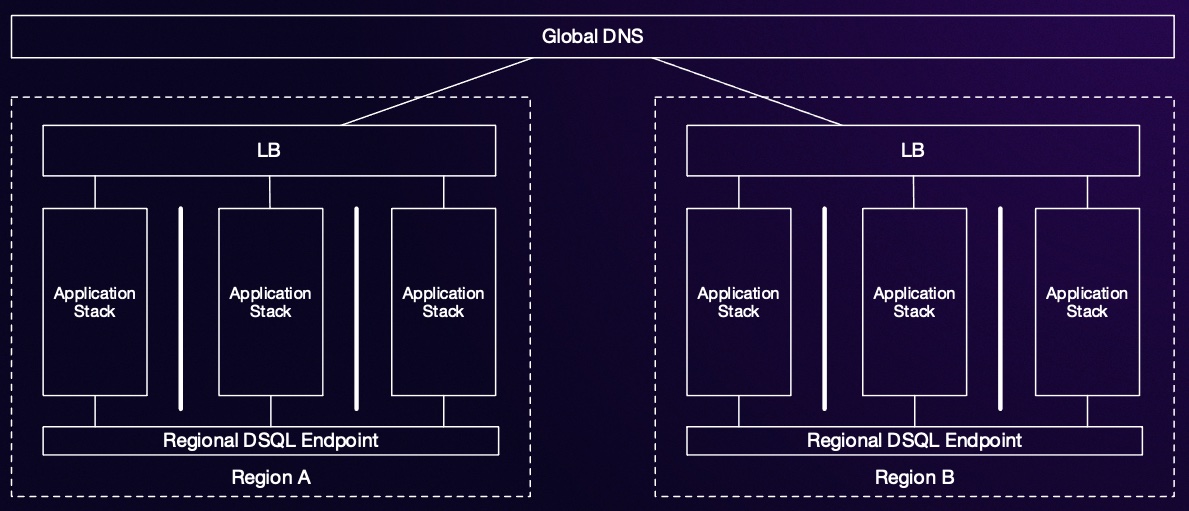
Here, we’ve built out an application architecture here across multiple AZs in each region, used the local DSQL endpoint in each region, and routed customers to the right region using latency-based DNS routing. Taking advantage of an active-active distributed database means that many applications don’t even need to know they’re running across multiple regions - and don’t need to be modified to handle failover, switchover, and other tasks. Re-routing traffic at the front door, and handing hard problems like replication and consistency over to Aurora DSQL, greatly simplifies this architecture.
Footnotes
- For now. Keep an eye out for more configuration and features in this space.
- Check out Jacob’s AWS Builder’s Library article on Avoiding fallback in distributed systems for why fallbacks and fail-over are good to avoid in high-reliability systems.
- Because replication in the happy case is a 2-of-3 quorum protocol across 3 regions, but if one fails it becomes a 2-of-2 protocol. Quorum protocols are great for latency, and going to 2-of-2 means that we can’t avoid waiting for the longest link in the system.
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com