About Me
My name is Marc Brooker. I like to build things that work, and do cool stuff. I like building big things. I also dabble in machining, welding, cooking, and skiing.I am an engineer at Amazon Web Services (AWS) in Seattle, where I work on agentic AI, especially safety and policy for agentic AI. Before that, I worked on EC2, EBS, databases, serverless, and serverless databases.
All opinions are my own.
Links
My Publications and Videos@marcbrooker on Mastodon @MarcJBrooker on Twitter
Is this blog written by AI?
Bélády’s Anomaly Doesn’t Happen Often
It was 1969. The Summer of Love wasn’t raging4, Hendrix was playing the anthem, and Forest Gump was running rampant. In New York, IBM researchers Bélády, Nelson, and Schedler were hot on the trail of something strange. They had a paging machine, a computer which kept its memory in pages, and sometimes moved those pages to storage. Weird1. It wasn’t only the machine that was weird, it was their performance results. Sometimes, giving the machine more memory made it slower. Without modern spook-hunting conveniences like Scooby Doo and Bill Murray, they had to hunt the ghost themselves.
What Bélády and team found is something now called Bélády’s anomaly. In their 1969 paper3, they describe it like this:
Running on a paging machine and using the FIFO replacement algorithm, there are instances when the program runs faster if one reduces the storage space allotted to it.
More generally, this can happen with any FIFO cache: growing the cache can lead to worse results. This could, in theory, be a big problem for any tuning system or process which makes the assumption that growing the cache leads to better performance2. This doesn’t happen with LRU. Just with FIFO, and with algorithms like LFU. Some point to Bélády’s anomaly as a good reason for avoiding FIFO caches, even in systems where the reduced read-time coordination and space overhead would be a big win.
But how frequent is Bélády’s anomaly really? Do we, as system builders, really need to avoid FIFO caches because of it?
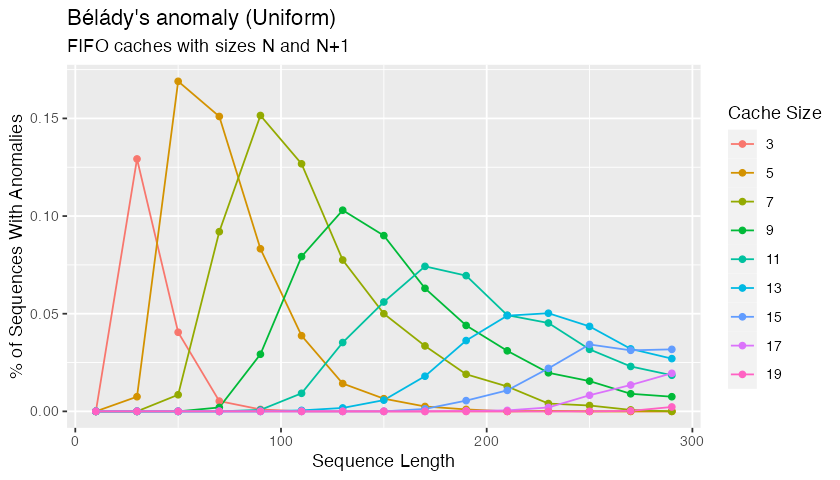
One way to answer that question is how often we’re likely to come across Bélády’s anomaly purely by chance. It turns out that it doesn’t happen very often at all. Starting with access patterns selected randomly with a uniform distribution of keys:
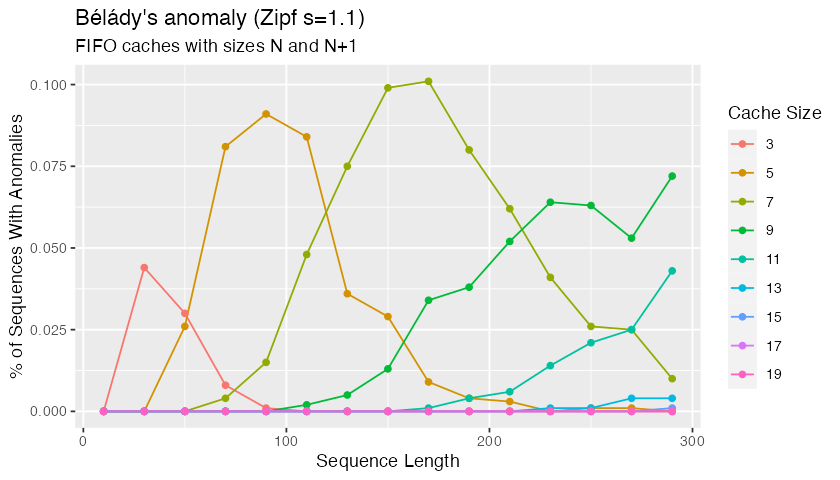
and with a Zipf distribution of keys:
In each simulation here, we’re comparing caches of size N and N+1, and counting the cases where the smaller cache has a superior hit rate. There are N+2 unique pages in the system, the number that seems to maximize the frequency of the anomaly.
These really don’t happen that frequently, with fewer than 0.175% of uniform access patterns showing the anomaly. Also, while the badness of the anomaly is unbounded, none of these randomly-found strings show more than a small number of additional hits.
We’re making the assumption that these random access patterns are representative of real-world access patterns. That’s likely to be close to true in multi-tenant and multi-workload systems with large numbers of users or workloads, but may not be true in single-tenant single-workload database. There’s also some risk that adversaries could construct strings which take advantage of this anomaly, but if that’s possible it also seems possible for adversaries to create uncachable workloads more generally.
As a systems builder, Bélády’s anomaly isn’t a big concern to me. As somebody who appreciates a good edge case, I just love it.
Correction: Bélády’s Anomaly in LFU caches
Juncheng Yang pointed out that I made a rather critical mistake in the first version of this post: I said that Bélády’s anomaly only occurs in FIFO, and doesn’t occur for other algorithms like LFU. I was mistaken: Bélády’s anomaly indeed can show up in LFU caches, although initial simulation results seem to suggest that this happens rather less often with LFU than FIFO5 (although with shorter sequences, an effect that I don’t yet really understand).
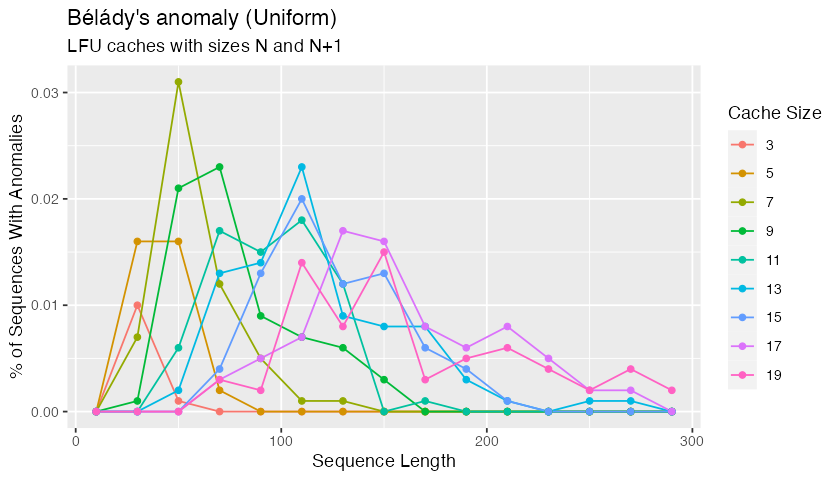
Juncheng also said that ARC has a significantly higher rate of anomalies than even FIFO. I haven’t had a chance to test that, but it makes intuitive sense. This change doesn’t alter my conclusion (Bélády’s anomaly probably isn’t worth worrying about), but it’s important to get these things right.
The next question on my mind is about algorithms like LRU-k6, which exist on some continuum between LRU and LFU.
Footnotes
- Weird enough that, these days, paging is just how computers work for the vast majority of machines.
- As Cristina Abad pointed out on Twitter.
- Like a lot of 1960s systems work, this paper is a delight. It’s easy to read, just five pages, and full of interesting analysis. Even the title, An anomaly in space-time characteristics of certain programs running in a paging machine, is delightful. Why can’t systems papers like this get published anymore?
- That was 1967.
- Initial results because I’m traveling, and so have to run shorter simulations because I don’t have access to the beefy machine I used for the ones above. And because I could easily have made another silly error here.
- Have I ever shared the story of how I made a fool of myself the first time I met the legendary Betty O’Neil (co-inventor of LRU-k, snapshot isolation, and many other things)?
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com