About Me
My name is Marc Brooker. I like to build things that work, and do cool stuff. I like building big things. I also dabble in machining, welding, cooking, and skiing.I am an engineer at Amazon Web Services (AWS) in Seattle, where I work on agentic AI, especially safety and policy for agentic AI. Before that, I worked on EC2, EBS, databases, serverless, and serverless databases.
All opinions are my own.
Links
My Publications and Videos@marcbrooker on Mastodon @MarcJBrooker on Twitter
Is this blog written by AI?
Container Loading in AWS Lambda
Back in 2019, we started thinking about how allow Lambda customers to use container images to deploy their Lambda functions. In theory this is easy enough: a container image is an image of a filesystem, just like the zip files we already supported. The difficulty, as usual with big systems, was performance. Specifically latency. More specifically cold start latency. For eight years cold start latency has been one of our biggest investment areas in Lambda, and we wanted to support container images without increasing latency.
But how do you take the biggest contributor to latency (downloading the image), increase the work it needs to do 40x (up to 10GiB from 256MiB), without increasing latency? The answer to that question is in our new paper On-demand Container Loading in AWS Lambda, which appeared at Usenix ATC’23.
In this post, I’ll pull out some highlights from the paper that I think folks might find particularly interesting.
Deduplication
The biggest win in container loading comes from deduplication: avoiding moving around the same piece of data multiple times. Almost all container images are created from a relatively small set of very popular base images, and by avoiding copying these base images around multiple times and caching them near where they are used, we can make things move much faster. Our data shows that something like 75% of container images contain less than 5% unique bytes.
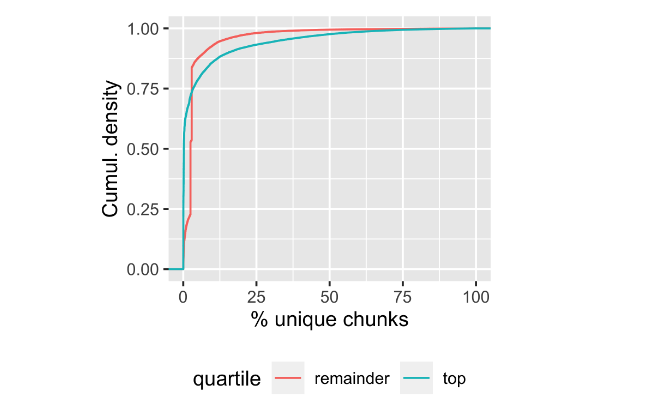
This isn’t a new observation, and several other container loading systems already take advantage of it. Most of the existing systems1 do this at the layer or file level, but we chose to do it at the block level. We unpack a snapshot (deterministically, which turns out to be tricky) into a single flat filesystem, then break that filesystem up into 512KiB chunks. We can then hash the chunks to identify unique contents, and avoid having too many copies of the same data in the cache layers.
Lazy Loading
Most of the data in container images isn’t unique, and even less of it is actually used by the processes running in the container (in general). Slacker by Harter et al was one of the first papers to provide great data on this. Here’s figure 5 from their paper:
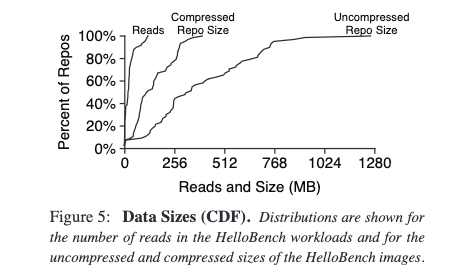
Notice the gap between reads and repo size? That’s the savings that are available from loading container data when it is actually read, rather than downloading the entire image. Harter et al found that only 6.5% of container data is loaded on average. This was the second big win we were going for: the ~15x acceleration available from avoiding downloading whole images.
In Lambda, we did this by taking advantage of the layer of abstraction that Firecracker provides us. Linux has a useful feature called FUSE provides an interface that allows writing filesystems in userspace (instead of kernel space, which is harder to work in). We used FUSE to build a filesystem that knows about our chunked container format, and responds to reads by fetching just the chunks of the container it needs when they are needed.
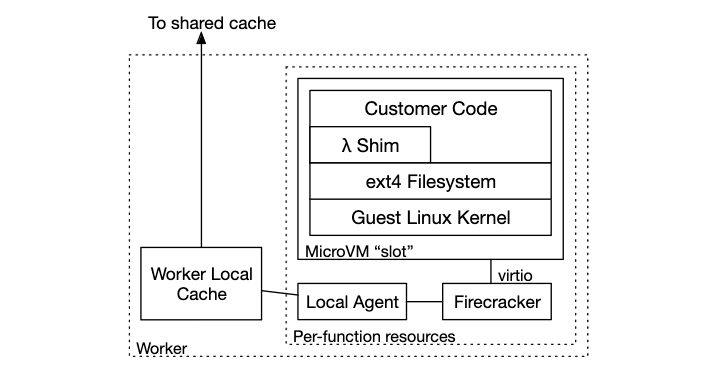
The chunks are kept in a tiered cache, with local in-memory copies of very recently-used chunks, local on-disk copies of less recent chunks, and per-availability zone caches with nearly all recent chunks. The whole set of chunks are stored in S3, meaning the cache doesn’t need to provide durability, just low latency.
Tiered Caching
The next big chunk of our architecture is that tiered cache: local, AZ-level, and authority in S3. As with nearly all data accesses in nearly all computer systems, some chunks are accessed much more frequently than others. Despite our local on-worker (L1) cache being several orders of magnitude smaller than the AZ-level cache (L2) and that being much smaller than the full data set in S3 (L3), we still get 67% of chunks from the local cache, 32% from the AZ level, and less than 0.1% from S3.
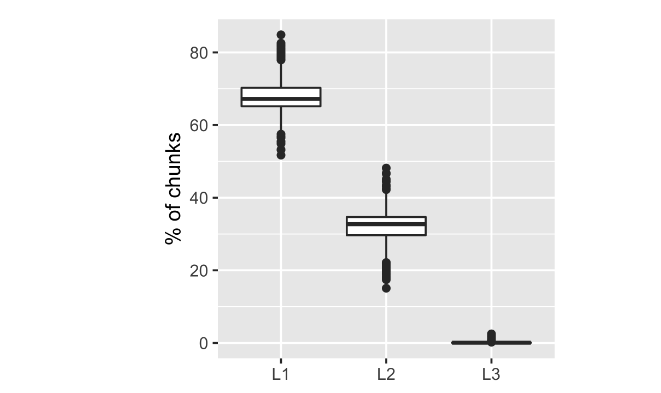
It’s not a surprise to anybody who builds computer systems that caches are effective, but the extreme effectiveness of this one surprised us somewhat. The per-AZ cache is extremely effective (perhaps too effective, which I’ll talk about in a future post).
Another interesting property of our cache is that we’re careful not to keep exactly one copy of the most common keys in the cache. We mix a little time-varying data, a salt, into the function that chooses the content-based names for chunks. This means that we cache a little more data than we need to, and lose a little bit of hit rate, but in exchange we reduce the blast radius of bad chunks. If we keep exactly one copy of the most popular chunks, corruption of that chunk could affect nearly all functions. With salt, the worst case of chunk loss touches only a small percentage of functions.
Erasure Coding
The architecture of our shared AZ-level cache is a fairly common one: a fleet of cache machines, a variant of consistent hashing to map chunk names onto caches, and an HTTP interface2. One thing that’s fairly unusual is that we’re using erasure coding to bring down tail latency and reduce the impact of cache node failures. I covered the tail latency angle in my post on Erasure Coding versus Tail Latency, but the operational angle is also important.
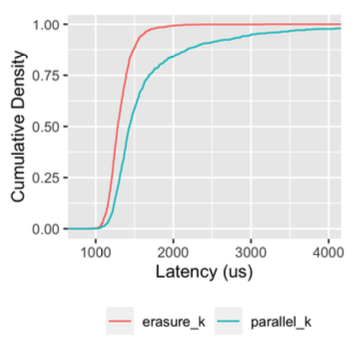
Think about what happens in a classic consistent hashed cache with 20 nodes when a node failure happens. Five percent of the data is lost. The hit rate drops to a maximum of 95%, which is a more than 5x increase in misses given that our normal hit rate is over 99%. At large scale machines fail all the time, and we don’t want big changes in behavior when that happens. So we use a technique called erasure coding to completely avoid the impact. In erasure coding, we break each chunk up into $M$ parts in a way that it can be recreated from any $k$. As long as $M - k >= 1$ we can survive the failure of any node with zero hit rate impact (because the other $k$ nodes will pick up the slack).
That makes software deployments easier too. We can just deploy to the fleet a box at a time, without carefully making sure that data has moved to new machines before we touch them. It’s a little bit of code complexity on the client side, in exchange for a lot of operational simplicity and fault tolerance.
On Architecture
The overall architecture of our container loading system consists of approximately 6 blocks. Three of those (ECR, KMS, S3) are existing systems with internal architectures of their own, and three (the flattening system, the AZ-level cache, and the on-worker loading components) are things that we designed and built for this particular project.
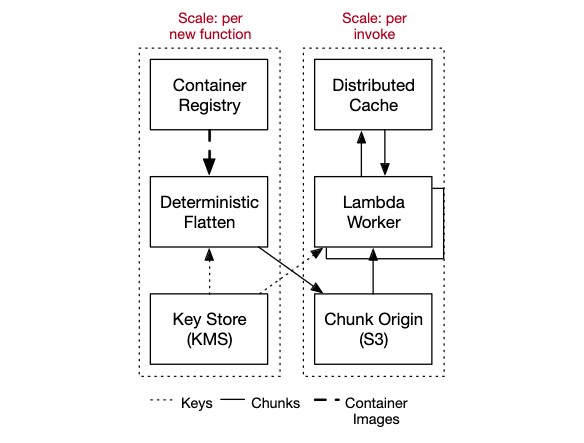
Each of those components has different scale needs, different performance needs, was deployed in different ways, and has different security needs. So we designed them as different components and they get their own block in the block diagram. These blocks, in turn, interact with the other blocks that make up Lambda, including the control plane that tracks metadata, the invoke plane that sends work to workers, and the isolation provided by Firecracker and related components.
All large systems are built this way, as compositions of components with different goals and needs. And, crucially, different groups of people responsible for building, operating, and improving them over time. Choosing where to put component boundaries is somewhat science (look for places where needs are different), somewhat art (what are the right APIs?), and somewhat fortune telling (how will we want to evolve the system in future?). I’m happy with what we did there, but also confident that in the long term we’ll want to adapt and change it. That’s the nature of system architecture.
However, I want to reiterate, that there is not one architectural pattern to rule them all. How you choose to develop, deploy, and manage services will always be driven by the product you’re designing, the skillset of the team building it, and the experience you want to deliver to customers (and of course things like cost, speed, and resiliency).
Conclusion
I loved writing this paper (with my co-authors) because it’s a perfect illustration of what excites me about the work I do. We identified a real problem for our customers, thought through solutions, and applied a mix of architecture, algorithms, and existing tools to solve the problem. Building systems like this, and watching them run, is immensely rewarding. Building, operating, and improving something like this is a real team effort, and this paper reflects deep work from across the Lambda team and our partner teams.
This system gets performance by doing as little work as possible (deduplication, caching, lazy loading), and then gets resilience by doing slightly more work than needed (erasure coding, salted deduplication, etc). This is a tension worth paying attention to in all system designs.
In Video
If you’d prefer to consume this blog post as a video, here’s the talk I have at ATC’23.
Footnotes
- There’s a fairly complete literature review in the paper. I’m not going to repeat it here, so if you’re interested in how similar systems do it, go check it out there.
- This was something of a surprise. We built to the prototype with HTTP (using reqwest and hyper), fully expecting to swap it out for a binary protocol. What we found was that the cache machines could easily saturate their 50Gb/s NICs without breaking a sweat, so we’re keeping HTTP for now.
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com