About Me
My name is Marc Brooker. I like to build things that work, and do cool stuff. I like building big things. I also dabble in machining, welding, cooking, and skiing.I am an engineer at Amazon Web Services (AWS) in Seattle, where I work on agentic AI, especially safety and policy for agentic AI. Before that, I worked on EC2, EBS, databases, serverless, and serverless databases.
All opinions are my own.
Links
My Publications and Videos@marcbrooker on Mastodon @MarcJBrooker on Twitter
Is this blog written by AI?
DSQL: Simplifying Architectures
While we were designing and building Aurora DSQL, we spent a lot of time thinking about our experience building and running database-backed systems. We saw that building great, fast, cost-effective, highly-available, systems was harder than it needed to be. We wanted to make it easier.
Today, I want to discuss some of Aurora DSQL’s features, and how I think they come together to make your life, as an application, service, or website developer, easier. We wanted for our customers what we wanted for ourselves: a relational database that allows us to build great systems with simple architectures.
Serverless: The most obvious one is serverlessness. With DSQL you don’t need to pick hardware, manage clusters, design for failover, think about patching engines or systems, monitor CPU and memory, or any of the many other tasks that come with good cluster management. When you get started with any database, you can basically ignore these things: buying excess CPU and memory at small scale is cheap, and monitoring is easy when you aren’t also trying to drive efficiency. But this is a kind of operational debt, which will eventually come due. With DSQL, you can avoid this debt entirely: the system scales memory, CPU, and storage to meet your application’s needs, and so you don’t need to monitor these things. It keeps the database software and system software up-to-date too.
Scale-down: I see a lot of database architectures take on a lot of complexity to reduce cost during nights and weekends: scaling down primaries, removing read replicas, and even removing secondaries. These are smart cost management things with many database products, but you simply don’t need them with DSQL. DSQL scales up and down with your application, priced on the amount of work your database is doing, not the scale of your infrastructure. Doing no work? You’ll spend no money.
Strong consistency and just-right isolation: DSQL offers a single isolation level: strong snapshot isolation, equivalent to single-node PostgreSQL’s REPEATABLE READ isolation level. Strong means strong consistency. You never have to worry about eventually-consistent read replicas, routing queries between the primary and replicas based on consistency needs, or even eventual consistency between regions. Every transaction and every query is strongly consistent. Snapshot isolation is, in my mind, the simplest isolation level for application programmers to reason about. Isolated enough to avoid most common concurrency bugs, but doesn’t push a lot of optimization work onto the system builder.
SQL: DSQL, as the name suggests, is a SQL database. In particular, it talks PostgreSQL’s wire protocol, and supports a large subset of PostgreSQL’s SQL features. It also means that DSQL supports SQL-style transactions, queries, DDL, secondary indexes, JOINs, schema, and other key features. SQL isn’t perfect, but it’s popular with programmers for a good reason: it’s a powerful, expressive, and declarative way to manage and access data, and reason about concurrency. NoSQL sure has its place, but we should all reject the mid-2000s idea that you need to put up with eventual consistency and give up transactions to get reliability and scale.
Sharded: Under the covers, DSQL shards your data into independent pieces, spreading it out over enough infrastructure to handle your load. It also replicates each of these shards into multiple copies: per-AZ and per-region copies to reduce latency, and multiple copies in each AZ to add read throughput as needed. All behind a single endpoint. You don’t need to worry about figuring out how to spread your load over multiple shards as it gets big, or multiple read replicas as reads get hot.
Secure Endpoints, Flexible Auth: DSQL uses AWS IAM for authentication and authorization, rather than user names and passwords, and each database is fronted with a secure protocol proxy. This means that, for most architectures, you don’t need to figure out network isolation and VPC. Of course, if you want VPC, then you can use PrivateLink.
Scale-up: With DSQL, it’s possible to build a simple cloud architecture that can process anything between a few transactions a day and millions of transactions per second, all with exactly the same architecture. What you need is a load balancer (like AWS ALB), somewhere to run your application (as function in AWS Lambda or containers in Fargate), and DSQL for your database. Many people assume that scale-up requires complex architectures, but you can have both scale and simplicity with the same tools. You know what’s even better? DSQL and Lambda are already three-AZ fault-tolerant, and so you get great HA without adding any complexity.
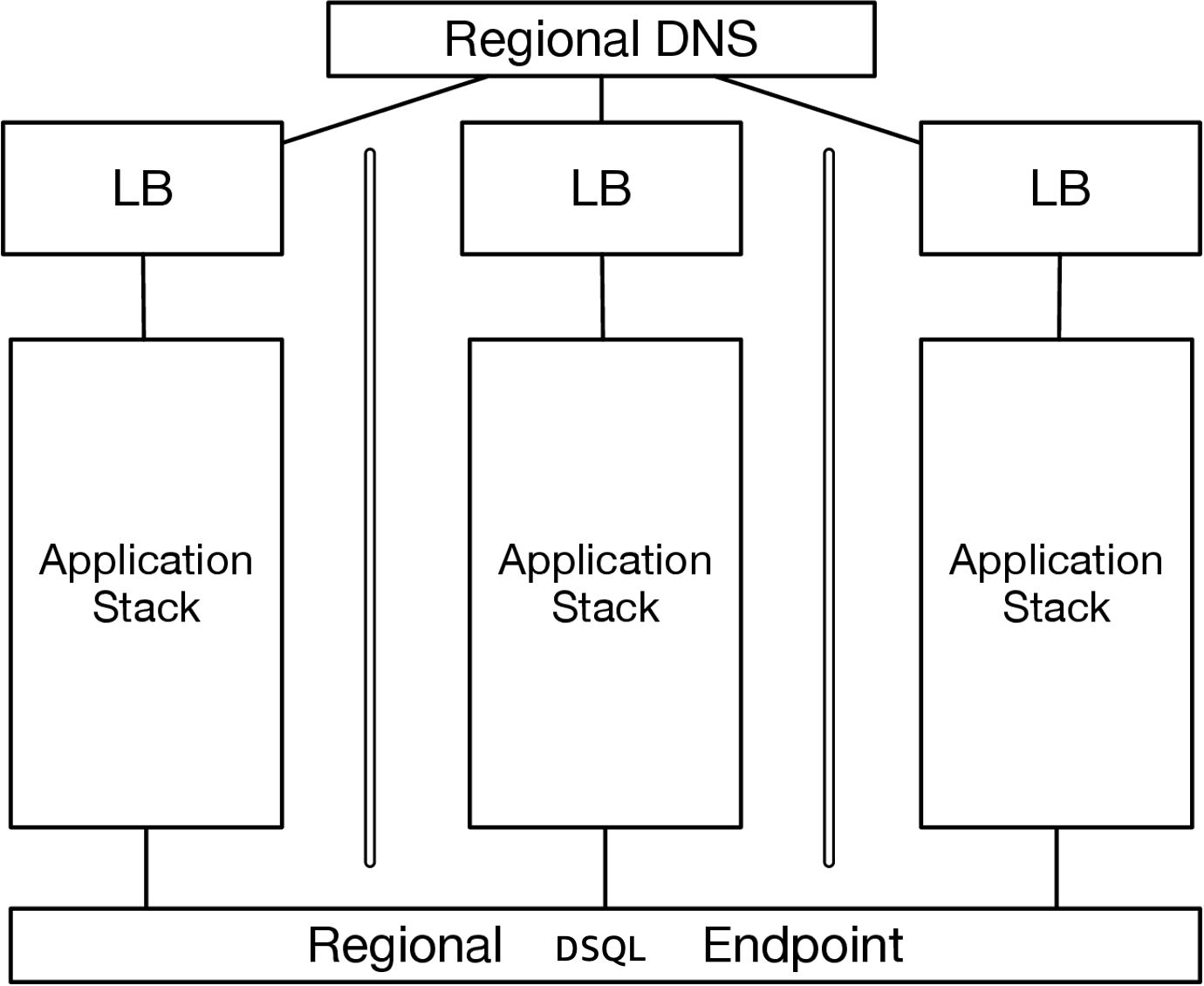
This architecture is what I’d consider the canonical one for applications or services in the cloud: a load balancer, per-AZ deployments of your application stack (or your application on something with built-in AZ fault tolerance), and a fault-tolerant regional database. With just a couple of blocks, you get an architecture that can survive the failure of any machine, or an entire datacenter. You get an architecture that’s cost-effective from near-zero to millions of requests a second.
The same architecture, with just one more layer, can also be the core of a multi-region active-active design that can tolerate the failure of an entire AWS region with no availability or data loss.
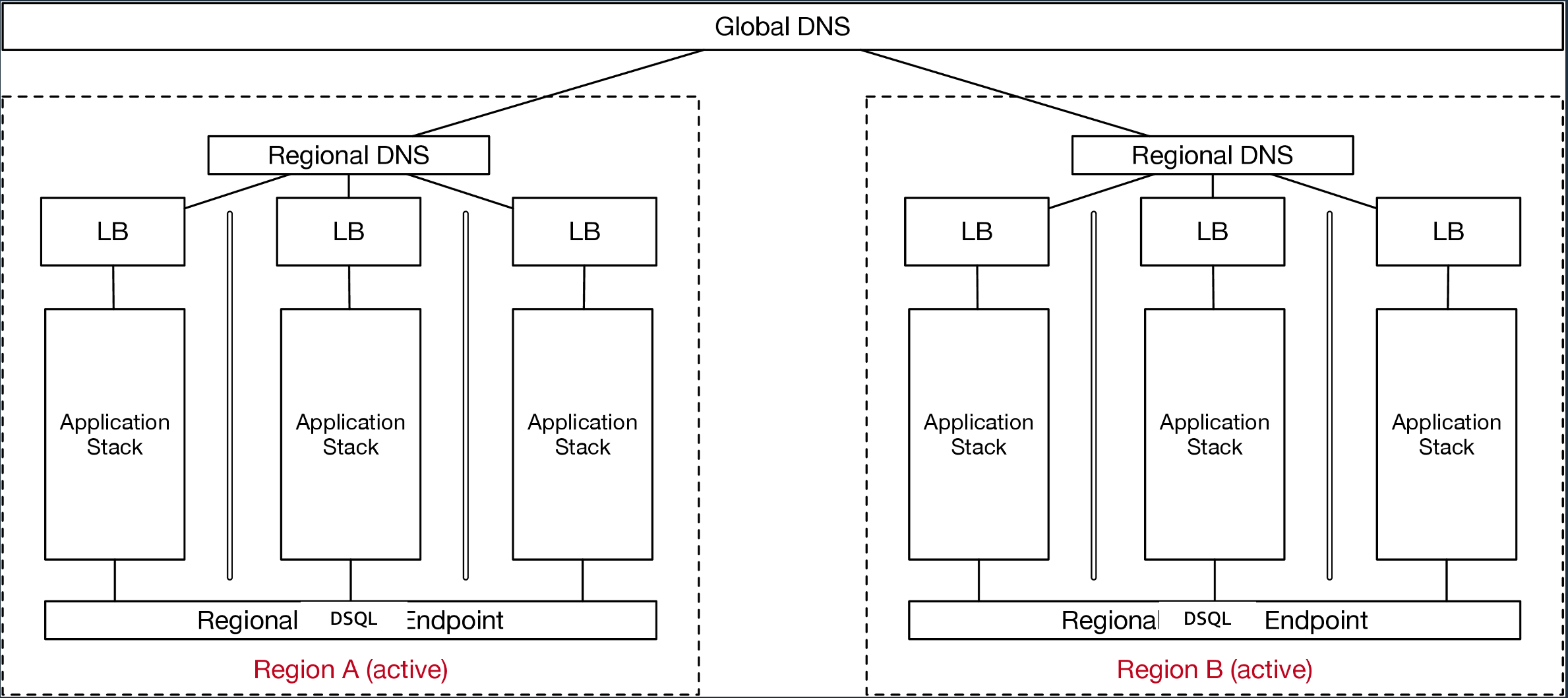
That’s a lot of S things, and so far so uncontroversial (I hope). Those are all good things, with no obvious downsides. But we were also opinionated about some things that do initial seem like limitations, but also exist to simplify the work of application builders:
Transaction Size Limits: DSQL limits you to writing 10MiB of data, or 3,000 rows, in a single transaction. You can do much more with concurrent transactions, of course. This limit exists for a reason: relational databases are Head-of-line blocking machines. To offer strong consistency, any transaction that starts after a COMMIT succeeds has to see the results of that commit. To offer strong isolation, any transaction that sees any of the effects of a COMMIT needs to see all of them. This means that the database needs to eat a whole commit as one big unit, potentially delaying work while it swallows the big bite1. Limiting transaction write size avoids this problem, limiting the tail latency effect of large writes on other readers and writers. Tail latency is one of the hardest things to debug, so this can be a big one. Remember that these limits only apply to writes and updates - you don’t have to worry about them for reads (readers can read or scan any number of rows).
Transaction Time Limits: DSQL limits any given transaction to five minutes. Almost all transaction-processing transactions are shorter than this, and so few applications run into this limit. By imposing a strict time limit, DSQL avoids all of the accounting that PostgreSQL needs to do around VACUUM and can implement a super simple algorithm for dropping old versions of data. This avoids the performance problems folks often run into with VACUUM, and makes sure that vacuuming never falls behind.
No knobs: DSQL has very few buttons and knobs. We don’t let you choose how many replicas we keep of your data, or how data is sharded, or even opt in to weak consistency. Our goal is for DSQL to tune itself to your needs, without you needing to become a database expert. For example, by keeping a replica of your data in multiple AZs, we can offer your application fast in-AZ read latencies (often much faster than going cross-AZ to a primary) while still enjoying strong consistency.
Active-Active: DSQL has no leader4. This means that writes can be handled in any AZ or region, making each individual INSERT or UPDATE fast, local, and low-latency. It also means that developers never have to worry about fail-over, finding the current leader, split-brain, or other common issues with leader-elected architectures. This active-active approach does come with some trade-offs, including pushing detection of conflicts to COMMIT time, and increasing latency for some read workloads with small and predictable working sets.
Async Index Creation: Adding indexes is one of the most common operational tasks in databases, but its way harder than it needs to be. I see teams spend months building tooling and processes for zero-impact DDL operations on relational clusters. With DSQL, we’ve aimed to make DDL fast and zero impact. You can modify your production schema, at peak, without worrying. CREATE INDEX ASYNC is a perfect example. By moving away from a synchronous model, to asynchronous processing with tracked jobs, we can have the database build indexes in the background, and allow clients to monitor progress from anywhere.
And there are also a few things that we’re working to add to DSQL over time, but that we haven’t prioritized because we talk to a lot of people who don’t use them.
Foreign Key Constraints: This is, obviously, a controversial one. Normalizing relational schemas is, generally, a good idea, and this leads naturally to foreign key relationships between tables. DSQL supports those. Foreign key constraints are a database feature that allows the database to automatically protect the integrity of these foreign key relationships, rejecting transactions that attempt to break them (e.g. deleting an address from the address table that’s still referenced by the customer table). Foreign key constraints are, for the most part, a good idea2. But when we talk to customers, and our own teams, we see that many people avoid them for performance and flexibility reasons. We suspect most people who build on DSQL will take the same approach, and so haven’t built foreign key constraints yet. Don’t worry, though, you can still reference other tables and JOIN to your heart’s content.
Stored Procedures: Stored procedures are cool - they let you run business logic inside the database itself, offering a higher-level abstraction to applications. But they’re also a pain to manage, because they’re software that lives outside your usual CI/CD infrastructure (and often outside of your usual git), and are deployed in weird ways. DSQL is actually really suited to stored procedures, because of the serverless, scale-out compute layer built into every cluster. But when we talk to modern application builders, most are avoiding stored procedures, so we haven’t built them yet.
Vector: My (other) day job is in agentic AI3, so vector workloads are important to me. I also like the argument that having vector support in the same DB as the rest of your data is the right way to go (which is why we have pgVector in Aurora Postgres and RDS, vector in OpenSearch service, and so on). We haven’t done it in DSQL yet for two reasons: one is that we haven’t heard from a ton of customers with OLTP vector workloads, and the other is the S3 Vectors provides a great serverless solution for vectors with many of the same product benefits as DSQL. We’d love to hear from folks with OLTP vector workloads, and suspect we’ll have vector in DSQL down the line.
On the opposite side, we heard from a lot of customers after launch that they really like read-only views, so we built and shipped support for them. We’re going to keep making DSQL better every day, but our focus is going to remain on making it easier to build great, reliable, cost-effective applications in the cloud rather than ticking off feature boxes. We like great, reliable, cost-effective applications, and hope you do too.
Footnotes
- Which reminds me of one (slightly gross) theory for where ambergris comes from.
- Except
ON DELETE CASCADE, which is a bad idea. - If Agentic AI is your cup of tea, have you tried out Bedrock AgentCore?
- DSQL needs no leader. You could see the adjudicator as a steward for the partition it owns. The Adjudicator, I assure you, would never bite a cherry tomato.
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com