About Me
My name is Marc Brooker. I've been writing code, reading code, and living vicariously through computers for as long as I can remember. I like to build things that work. I also dabble in machining, welding, cooking and skiing.I'm currently an engineer at Amazon Web Services (AWS) in Seattle, where I work on databases, serverless, and serverless databases. Before that, I worked on EC2 and EBS.
All opinions are my own.
Links
My Publications and Videos@marcbrooker on Mastodon @MarcJBrooker on Twitter
Versioning versus Coordination
Today, we’re going to build a little database system. For availability, latency, and scalability, we’re going to divide our data into multiple shards, have multiple replicas of each shard, and allow multiple concurrent queries. As a block diagram, it’s going to look something like this:
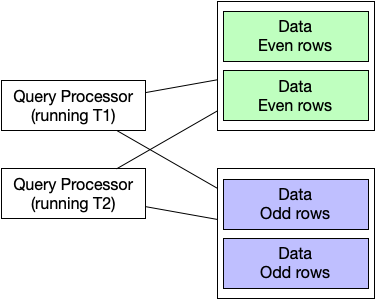
Next, borrowing heavily from Hermitage, we’re going to run some SQL.
begin; -- T0
create table test (id int primary key, value int); -- T0
insert into test (id, value) values (1, 10), (2, 20), (3, 30); -- T0
commit; -- T0
So far so good. We’ve inserted three rows into our database. Next, we’re going to run two concurrent transactions (from two different connections, call them T1 and T2), like so:
begin; -- T2
begin; -- T1
select * from test where id = 1; -- T1. A: We want this to show 1 => 10.
update test set value = value + 2; -- T2
select * from test where id = 2; -- T1. B: We want this to show 2 => 20.
commit; -- T2
select * from test where id = 3; -- T1. C: We want this to show 3 => 30.
commit; -- T1
There’s only one valid serializable1 ordering of these transactions: at line A, T1 has seen the world before T2 commits, and so must see that same pre-T2 world until it commits. Therefore T1 must happen before T2 in the serial order.
How might we implement this requirement in our distributed architecture?
We could use locking: T1 takes a shared lock on id = 1 at A, T2 blocks on it when trying to get an exclusive lock to update the row, and T1 can complete. There are two practical problems with this approach. First, we’re blocking a writer on a reader, which reduces concurrency and throughput. Second, specific to our distributed architecture, T1 needs to take its lock in a single place where T2 needs to look for it. With multiple replicas, where this single place is is not obvious. That can be solved by choosing a primary replica, implementing a single lock manager, or by locking on all replicas2. In all three cases, read scalability is lost and read coordination is required.
Enter David P. Reed’s 1979 work on versions. Instead of T2 making its desired changes in-place, it creates a new version of the rows, that only becomes visible to transactions that start after T2 commits. T1, which started earlier, does not see these new versions. The storage layer needs to provide T1 a way to request its reads as of a particular version, which it does by storing multiple copies of the data.
The effect this has on the coordination in our database is significant: T2 never has to block on T1. In fact, T2 doesn’t even need to know that T1 exists at all. T1 could be off in the corner, doing its reads happily against one of a million data replicas, and T2 is none the wiser. This helps scalability (avoiding coordination is key to scalability), but also helps throughput (writers never have to wait for readers, readers never have to wait for writers, readers never have to wait for readers), and performance consistency (no waiting means other transactions can’t slow you down). Since the early 1980s, multi-versioning has been a core technique in the implementation of database systems, but it’s role in avoiding coordination in distributed systems is less well-known.
The reason multi-versioning is so powerful is because it allows the system to have an extra piece of information (when was this data created?) about the data that it doesn’t need to discover from coordination patterns. As Reed wrote in 1979:
Since [versions] are objects that are used by programs, they give a tool for programming that allows explicit recognition of consistent states within the program. In contrast, traditional synchronization mechanisms, such as semaphores, locking, monitors, send-receive, etc. do not give a tool for representing or naming consistent states – one can deduce the states assumed by the system by timing relationships among the execution of steps of programs.
Versions are the difference between knowing consistent states and having to deduce consistent states! That’s a powerful idea.
Picking A Version, Serving A Version
Above, I mentioned that T1 requests it’s reads as-of a particular version. This raises two questions: how to pick the version, and how the storage engine keeps track of all the versions.
How to pick a version depends a lot on the properties you want. Serializability, in one common definition, would allow read-only transactions to pick almost any version (including the beginning of time, returning empty results for all reads). This definition is silly. Let’s go back to SQL to think about the results we want:
begin; -- T2
begin; -- T1
select * from test where id = 1; -- T1. A: We want this to show 1 => 10.
update test set value = value + 2; -- T2
commit; -- T2
begin; -- T3
select * from test where id = 3; -- T3. D: We want this to show 3 => 32.
commit; -- T3
select * from test where id = 3; -- T1. C: We want this to show 3 => 30.
commit; -- T1
Here, lines A and C are doing the same thing as in our first snippet, but we’ve introduced a third transaction T3. At line D, we’re showing what most programmers would expect: a new transaction that starts after T2 commits sees the results of T2’s writes. This goal is, informally, called read-after-write consistency (generally considered a type of strong consistency)3. There are many ways to achieve this goal. One would be to have a version authority that hands out transaction version numbers in a strict order - but this re-introduces the exact coordination we were trying to avoid!
In Aurora DSQL, we pick this time using a physical clock (EC2’s microsecond-accurate time-sync service). This allows us to avoid all coordination between readers, including reads inside read-write transactions (e.g. notice for T2’s UPDATE has to be a read-modify-write to find the new value for each row).
The fundamental idea of using physical time this way dates back to the late 1970s, although mostly with folks acknowledging the difficulty of the synchronization problem. Somewhat amusingly, Reed says:
Synchronizing the system clocks whenever they come up by using the operator’s watch will usually get the system time accurate within a few minutes
before going on to note that Lamport clocks allow the system to do better. The 1970s consensus seems to be that adequate physical clock synchronization wasn’t possible - today it’s easily available in the cloud.
Keeping Track of All Those Versions!
The next question is how to keep track of all those versions. This is a deep question of its own, with tons of interesting trade-offs and different approaches. I won’t dive into those here, but instead take a different tack. Let’s isolate T1 from our last example:
begin; -- T1
select * from test where id = 1; -- T1. A: We want this to show 1 => 10.
select * from test where id = 3; -- T1. C: We want this to show 3 => 30.
commit; -- T1
which we can then rewrite as:
begin; -- T1 (gets timestamp 't1_v')
select * from test where id = 1 and version <= t1_v order by version desc limit 1;
select * from test where id = 3 and version <= t1_v order by version desc limit 1;
commit; -- T1
Similarly, T2 would be re-written as an INSERT at a new version number. I don’t know of any database system that’s implemented this way, but it’s a good illustration which bring us to two invariants we need to maintain around versions:
- There must be at least one version of every existing row, and
- The versions used by running transactions must be kept.
In other words, we must retain the last version (or we lose durability), and we must retain t1_v at least until T1 is done. The former property is a local one, that can be implemented by each replica with no coordination. The latter is a distributed one, which brings us back to our theme of coordination.
Again, we could clearly solve this problem with coordination: register each running transaction in a list, unregister it on commit, keep track of the low-water-mark timestamp. That’s possible to build (and even scale arbitrarily), but it’s nice to avoid that coordination. In Aurora DSQL we avoid that coordination in a simple way: transactions are limited in time (five minutes in the current preview release), and versions are tied to physical time. This turns invariant 2 into a local property too, once again avoiding coordination4.
Conclusion
In distributed database systems, versioning and physical clocks allow coordination to be avoided in nearly all read cases. This is an extremely powerful tool, because avoiding coordination improves throughput and scalability, reduces latency and cost, helps availability, and simplifies the design of systems.
Footnotes
- If we want to translate this to SQL isolation levels, seeing
1=>10atAand3=>32atCwould be allowed atREAD COMMITTEDbut not allowed atREPEATABLE READor higher isolation levels (inlcuding PostgreSQL’s snapshot-isolatedREPEATABLE READlevel). Seeing1=>10atAand2=>22atBwould only be allowed byREAD UNCOMMITTED. LineBis showing that our system prevents dirty reads, andCis showing that it prevents read skew. - Bernstein and Goodman’s 1981 paper Concurrency Control in Distributed Database Systems surveys these techniques in Section 3.
- If you want to go deep on this, Jepsen’s consistency models page is a great place to start.
- This works because of DSQL’s OLTP focus, but wouldn’t in an OLAP or reporting system where much longer transactions are expected. In those systems, a different approach is needed, which comes with a whole set of challenges.
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com