About Me
My name is Marc Brooker. I like to build things that work, and do cool stuff. I like building big things. I also dabble in machining, welding, cooking, and skiing.I am an engineer at Amazon Web Services (AWS) in Seattle, where I work on agentic AI, especially safety and policy for agentic AI. Before that, I worked on EC2, EBS, databases, serverless, and serverless databases.
All opinions are my own.
Links
My Publications and Videos@marcbrooker on Mastodon @MarcJBrooker on Twitter
Is this blog written by AI?
Give Your Tail a Nudge
We all care about tail latency (also called high percentile latency, also called those times when your system is weirdly slow). Simple changes that can bring it down are valuable, especially if they don’t come with difficult tradeoffs. Nudge: Stochastically Improving upon FCFS presents one such trick. The Nudge paper interests itself in tail latency compared to First Come First Served (FCFS)1, for a good reason:
While advanced scheduling algorithms are a popular topic in theory papers, it is unequivocal that the most popular scheduling policy used in practice is still First-Come First-Served (FCFS).
This is all true. Lots of proposed mechanisms, pretty much everybody still uses FCFS (except for some systems using LIFO2, and things like CPU and IO schedulers which often use more complex heuristics and priority levels3). But this simplicity is good:
However, there are also theoretical arguments for why one should use FCFS. For one thing, FCFS minimizes the maximum response time across jobs for any finite arrival sequence of jobs.
The paper then goes on to question whether, despite this optimality result, we can do better than FCFS. After all, minimizing the maximum doesn’t mean doing better across the whole tail. They suggest a mechanism that does that, which they call Nudge. Starting with some intuition:
The intuition behind the Nudge algorithm is that we’d like to basically stick to FCFS, which we know is great for handling the extreme tail (high 𝑡), while at the same time incorporating a little bit of prioritization of small jobs, which we know can be helpful for the mean and lower 𝑡.
And going on to the algorithm itself:
However, when a “small” job arrives and finds a “large” job immediately ahead of it in the queue, we swap the positions of the small and large job in the queue. The one caveat is that a job which has already swapped is ineligible for further swaps.
Wow, that really is a simple little trick! If you prefer to think visually, here’s Figure 1 from the Nudge paper:
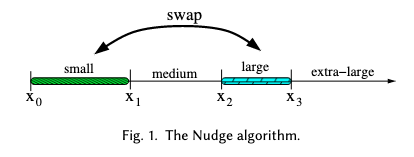
But does it work?
I have no reason to doubt that Nudge works, based on the analysis in the paper, but that analysis is likely out of the reach of most practitioners. More practically, like all closed-form analysis it asks and answers some very specific questions, which isn’t as useful for exploring the effect that applying Nudge may have on our systems. So, like the coward I am, I turn to simulation.
The simulator (code here) follows the simple simulation approach I like to apply. It considers a system with a queue (using either Nudge or FCFS), a single server, Poisson arrivals, and service times picked from three different Weibull distributions with different means and probabilities. You might call that an M/G/1 system, if you like Kendall’s Notation.
What we’re interested in, in this simulation, is the effect across the whole tail, and for different loads on the system. We define load (calling it ⍴ for traditional reasons) in terms of two other numbers: the mean arrival rate λ, and the mean completion rate μ, both in units of jobs/second.
\[\rho = \frac{\lambda}{\mu}\]Obviously when $\rho > 1$ the queue is filling faster than it’s draining and you’re headed for catastrophe more quickly than you think. Considering the effect of queue tweaks for different loads seems interesting, because we’d expect them to have very little effect at low load (the queue is almost always empty), and want to make sure they don’t wreck things at high load.
Here are the results, as a cumulative latency distribution, comparing FCFS with Nudge for three different values of ⍴:
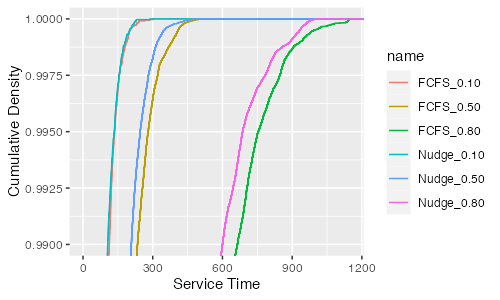
That’s super encouraging, and suggests that Nudge works very well across the whole tail in this model.
More questions to answer
There are a lot more interesting questions to explore before putting Nudge into production. The most interesting one seems to be whether it works with our real-world tail latency distributions, which can have somewhat heavy tails. The Nudge paper says:
In this paper, we choose to focus on the case of light-tailed job size distributions.
but defends this by saying (correctly) that most real-world systems truncate the tails of their job size distributions (with mechanisms like timeouts and limits):
Finally, while heavy-tailed job size distributions are certainly prevalent in empirical workloads …, in practice, these heavy-tailed workloads are often truncated, which immediately makes them light-tailed. Such truncation can happen because there is a limit imposed on how long jobs are allowed to run.
Which is almost ubiquitous in practice. It’s very hard indeed to run a stable distributed system where job sizes are allowed to have unbounded cost4. Whether our tails are bounded enough for Nudge to behave well is a good question, which we can also explore with simulation.
The other important question, of course, is how it generalizes to larger systems with multiple layers of queues, multiple servers, and more exciting arrival time distributions. Again, we can explore all those questions through simulation (you might be able to explore them in closed-form too, but that’s beyond my current skills).
Summary Overall, Nudge is a very cool result. In its effectiveness and simplicity it reminds me of the power of two random choices and Always Go Left. It may be somewhat difficult to implement, especially if the additional synchronization required to do the compare-and-swap dance is a big issue.
Footnotes
- You might also call this First In First Out, or FIFO.
- First Come Last Served?
- IO Schedulers are an especially interesting topic, although one that has become less interesting with the rise of SSDs (and, to an extent, smarter HDD interfaces like NCQ). Old school IO schedulers like Linux’s elevator could bring amazing performance gains by reducing head movement in hard drives. Most folks these days are just firing their IOs at an SSD (with a noop scheduler).
- Some systems do, of course, especially data analytics systems which could be counting the needles in a very large haystack. These systems do turn out to be difficult to build (although building them in the cloud and being able to share the same capacity pool between different uncorrelated workloads from different customers helps a lot).
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com